




Comment DiDi Food a transformé la recherche d’épicerie à travers l’Amérique latine

Réduction de 19 %
dans les requêtes sans résultat obtenues grâce à la recherche vectorielle sémantique Milvus
Augmentation de 4 %
conversions dans le panier grâce à la correspondance sémantique de produits optimisée par Milvus
15 % des requêtes
bénéficient désormais de la recherche vectorielle, en complément de la recherche textuelle traditionnelle
Récupération vectorielle en moins d’une seconde
avec l’indexation IVF_FLAT de Milvus et la similarité par produit scalaire
À propos de DiDi Food
DiDi, leader mondial du VTC avec plus de 800 millions d’utilisateurs dans le monde, a lancé DiDi Food — son service de livraison de courses — dans 12 grandes villes d’Amérique latine, notamment au Mexique, en Colombie et au Costa Rica. En s’appuyant sur leur réseau logistique existant et leurs capacités d’optimisation en temps réel, ils ont atteint une croissance remarquable : 2 millions d’utilisateurs actifs mensuels, 500 000 commandes quotidiennes et plus de 120 millions de dollars de GMV au T1 2025 — le tout en seulement six mois.
La plateforme livre des produits frais et des essentiels ménagers en 30 à 45 minutes, avec des magasins partenaires proposant jusqu’à 30 millions de SKU chacun. Opérant sur des marchés variés avec des interactions multilingues, une tarification dynamique et une gestion des stocks en temps réel, DiDi Food a bâti une base commerciale impressionnante. Mais à mesure que leur échelle augmentait, la complexité consistant à aider des millions de clients à trouver exactement ce dont ils avaient besoin dans d’immenses catalogues de produits augmentait elle aussi. C’est là que la base de données vectorielle Milvus a transformé leurs capacités de recherche, en permettant une compréhension sémantique qui fonctionne entre les langues et gère le désordre réel de la façon dont les gens effectuent réellement leurs recherches.
Le défi de la recherche : quand Elasticsearch basé sur les mots-clés atteint ses limites
L’équipe d’ingénierie de DiDi a été confrontée aux limitations qui affectent leur base de données Elasticsearch basée sur les mots-clés. De simples fautes d’orthographe, le code-switching ou des descriptions non conventionnelles conduisaient souvent à des pages de résultats vides, créant des frictions dans l’expérience d’achat.
Taux élevés de « Aucun résultat » : la perte de revenus cachée
DiDi Food faisait face à un problème critique : trop de recherches client ne renvoyaient aucun résultat, entraînant l’abandon de sessions d’achat et une perte de revenus. Des exemples réels tirés des données de recherche de DiDi ont révélé trois causes principales à l’origine de ces échecs.
Les fautes de frappe et d’orthographe étaient les coupables les plus courants. Les utilisateurs tapaient « Genjibr » lorsqu’ils cherchaient « Jengibre » (gingembre), « hedaho » au lieu de « HELADO » (glace), ou « Kellongs » pour « Kelloggs ». Leurs systèmes de recherche par mots-clés existants, alimentés par Elasticsearch, ne pouvaient pas combler ces petits écarts orthographiques pourtant critiques.
Les artefacts de méthode de saisie créaient un autre obstacle. Les claviers mobiles et différents systèmes de saisie généraient des variations Unicode inhabituelles comme « 𝑤𝑖𝑛𝑒 » au lieu de « wine », « 𝑏𝑎𝑛𝑎𝑛𝑎 » pour « banana », ou « 𝑐ℎ𝑜𝑐𝑜𝑙𝑎𝑡𝑒𝑠 » pour « chocolates ». Ces problèmes techniques d’encodage empêchaient les clients de trouver des produits qui étaient clairement en stock.
Les requêtes en langues mixtes représentaient le plus grand défi sur les marchés latino-américains. Les clients recherchaient naturellement « apple juice orgánico » ou « leche sin lactosa », combinant des termes anglais et espagnols. Les variations régionales aggravaient le problème : le même produit pouvait porter des noms différents au Mexique, en Colombie et au Costa Rica.
Chaque recherche infructueuse représentait un client frustré et une perte de revenus directe. Pour une plateforme traitant 500 000 commandes quotidiennes, même un faible pourcentage de requêtes sans résultat peut se traduire par un impact commercial significatif.
Scalabilité et complexité multilingue
Au-delà des échecs de recherche individuels, DiDi faisait face à des défis systémiques qui menaçaient sa capacité à passer à l’échelle. L’indexation textuelle de dizaines de millions de noms de SKU distincts faisait gonfler les coûts de stockage et dégradait les performances des requêtes à mesure que leur catalogue de produits s’étendait à plusieurs pays.
La complexité multilingue allait plus loin que les requêtes en langues mixtes. Opérer au Mexique, en Colombie, au Costa Rica et sur d’autres marchés latino-américains signifiait que le même produit pouvait avoir des noms complètement différents dans chaque région. « Palta » dans certains pays, « aguacate » dans d’autres — les deux désignant l’avocat. Les systèmes traditionnels par mots-clés alimentés par Elasticsearch nécessitaient de maintenir des index séparés pour chaque variation régionale, ce qui multipliait les besoins de stockage et compliquait la maintenance.
Les nuances culturelles et linguistiques ont créé des obstacles supplémentaires. L’argot local, les variations de noms de marque et même les différents systèmes de mesure (métrique vs impérial) ont tous contribué aux échecs de recherche. Une approche basée sur les mots-clés nécessiterait de cartographier manuellement des milliers de variations régionales — une tâche impossible à l’échelle de DiDi.
L’équipe d’ingénierie de DiDi avait besoin de toute urgence d’une solution capable de surmonter ces défis et de comprendre l’intention derrière les requêtes des utilisateurs, indépendamment de la langue, de la région ou de la manière dont les clients choisissaient d’exprimer leurs besoins.
La solution : créer un moteur de recherche sémantique avec Milvus
Le système propulsé par Elasticsearch peine à gérer la diversité linguistique et la variabilité des saisies utilisateur, car il traite les mots comme des jetons distincts plutôt que comme des concepts porteurs de sens. Les bases de données vectorielles, toutefois, peuvent comprendre le sens sémantique et l’intention des requêtes des utilisateurs grâce aux embeddings vectoriels et renvoyer des résultats plus précis et pertinents, indépendamment de la langue ou des fautes d’orthographe.
L’équipe d’ingénierie de DiDi a décidé de créer un moteur de recherche sémantique en s’appuyant sur des modèles d’embedding multilingues et une base de données vectorielle. Le modèle d’embedding convertit à la fois les noms et descriptions de produits ainsi que les requêtes des utilisateurs en embeddings vectoriels qui représentent leur signification sémantique dans un espace à haute dimension, tandis que la base de données vectorielle stocke ces embeddings et effectue une recherche sémantique en calculant les distances entre les vecteurs de requête et les vecteurs de produits.
Après une évaluation minutieuse, ils ont choisi jina-embeddings-v3 comme modèle d’embedding principal, car il projette du texte provenant de différentes langues dans le même espace mathématique à haute dimension. Cela signifie que des requêtes pour "苹果" (chinois), "apple" (anglais) ou "manzana" (espagnol) produisent des vecteurs presque identiques, permettant une correspondance interlingue précise sans avoir besoin de systèmes de traduction complexes. Même les entrées mal orthographiées ou phonétiquement similaires produisent des vecteurs proches des termes corrects.
DiDi a choisi Milvus comme base de données vectorielle en raison de sa maturité open source, de sa capacité à évoluer horizontalement jusqu’à des milliards de vecteurs, de sa latence en millisecondes, de son architecture éprouvée à haut débit et de son riche ensemble de fonctionnalités.
Architecture des données et stratégie d’optimisation
Pour prendre en charge une récupération vectorielle à faible latence sur 30 millions de SKU tout en préservant les associations au niveau des magasins, les ingénieurs de DiDi ont mis en œuvre plusieurs optimisations clés.
Plutôt que de stocker des vecteurs individuels pour chaque combinaison SKU-magasin, ils ont fusionné les noms d’articles identiques en entrées vectorielles uniques avec les identifiants de magasins correspondants stockés dans des tableaux. Cette approche a réduit leur bibliothèque vectorielle de 30 millions d’entrées à 200 000 vecteurs uniques, diminuant considérablement l’utilisation de la mémoire tout en maintenant une couverture complète des produits.
L’équipe a choisi une configuration d’index
IVF_FLATdans Milvus, privilégiant la précision de recherche plutôt que la complexité de la compression. Lorsque les utilisateurs interrogent le système, Milvus renvoie les top-k vecteurs les plus similaires depuis l’index agrégé, suivi d’un filtrage rapide par identifiant de magasin afin d’isoler les articles disponibles dans l’emplacement actuel de l’acheteur.Pour la fraîcheur des données, DiDi a adopté un cycle de mise à jour nocturne T+1. Les SKU nouveaux et mis à jour sont regroupés quotidiennement, ré-embeddés à l’aide de clusters GPU, puis envoyés pour actualiser la collection Milvus. Cette stratégie équilibre l’actualité des données et l’efficacité computationnelle sur leur immense catalogue de produits.
Conception du schéma Milvus
Le schéma de collection reflète les exigences spécifiques de DiDi pour la recherche de produits d’épicerie, en équilibrant flexibilité et performance :
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="embedding using jina-embeddings-v3",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
Génération d’embeddings accélérée par GPU
La génération initiale d’embeddings basée sur CPU avec le modèle jina-embeddings-v3 entraînait une latence inacceptable de 5 secondes par enregistrement. Pour atteindre des performances en temps réel, DiDi a déployé des instances GPU sur sa plateforme Luban, réduisant le temps d’embedding à environ 50 millisecondes par requête :
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
Architecture de pipeline de recherche hybride
Plutôt que de remplacer entièrement leur infrastructure existante, DiDi a implémenté Milvus comme complément intelligent à leur système Elasticsearch établi. La conception à double pipeline permet à Elasticsearch de gérer les requêtes par mots-clés standard tandis que Milvus fournit une compréhension sémantique pour les cas complexes.
Le flux de recherche fonctionne selon les étapes suivantes :
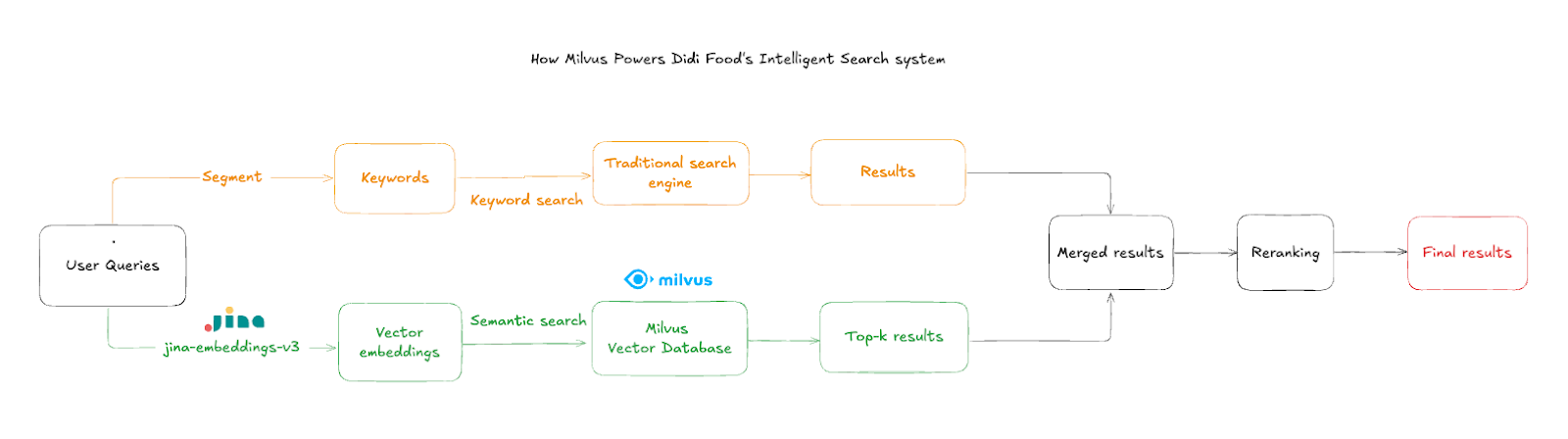
Saisie de la requête utilisateur : les clients saisissent des noms ou descriptions de produits, souvent avec des fautes de frappe ou dans plusieurs langues
Embedding de texte : le système utilise
jina-embeddings-v3pour convertir l’entrée en vecteurs sémantiques de haute dimension en ~50 msRecherche par similarité : Milvus interroge les vecteurs de produits agrégés pour trouver les correspondances sémantiques les plus proches
Filtrage par magasin : les résultats sont filtrés par ID de magasin afin de garantir que seuls les articles en stock dans le magasin actuel sont affichés
Fusion des résultats : les résultats vectoriels sont combinés avec les résultats Elasticsearch lorsque la recherche traditionnelle produit des résultats insatisfaisants, offrant une expérience de recherche plus riche et plus complète
Le filtrage au niveau du magasin est essentiel à l’expérience utilisateur, car il garantit que les résultats appartiennent au contexte de localisation actuel de l’acheteur. Le système emploie une agrégation intelligente des résultats : lorsque Elasticsearch produit des résultats insatisfaisants, les articles sémantiquement pertinents de Milvus complètent la réponse.
Résultats de performance et impact réel
L’implémentation de Milvus par DiDi a apporté des améliorations concrètes sur des indicateurs métier critiques.
Le système a permis une réduction de 19 % des requêtes sans résultat, ce qui signifie que près d’une recherche auparavant échouée sur cinq renvoie désormais des produits pertinents, récupérant directement des opportunités de revenus perdues. Pour une plateforme traitant 500 000 commandes quotidiennes, ce taux de récupération représente une valeur commerciale significative.
La recherche vectorielle est déclenchée pour 15 % du total des requêtes, complétant la recherche textuelle traditionnelle précisément lorsque la compréhension sémantique apporte de la valeur sans surcharger le pipeline de requêtes principal. Plus significativement, les utilisateurs exposés aux articles rappelés par vecteurs montrent une augmentation de 4 % des conversions d’ajout au panier, démontrant qu’une meilleure pertinence de recherche se traduit par un comportement d’achat mesurable.
Le système gère désormais les requêtes dans plusieurs langues, notamment l’anglais, l’espagnol, le chinois, le coréen et le japonais, avec des améliorations de précision particulièrement notables pour l’espagnol, crucial pour la présence de DiDi sur le marché latino-américain. Les tests de performance multilingues ont révélé la puissance de la compréhension sémantique : les recherches pour « Liquid Foundation » fonctionnent tout aussi bien que les utilisateurs saisissent le terme anglais, le chinois « 液体妆前乳 » ou l’espagnol « Base de maquillaje líquida ». Le système comble les écarts linguistiques qui mettraient complètement en échec les approches traditionnelles par mots-clés.
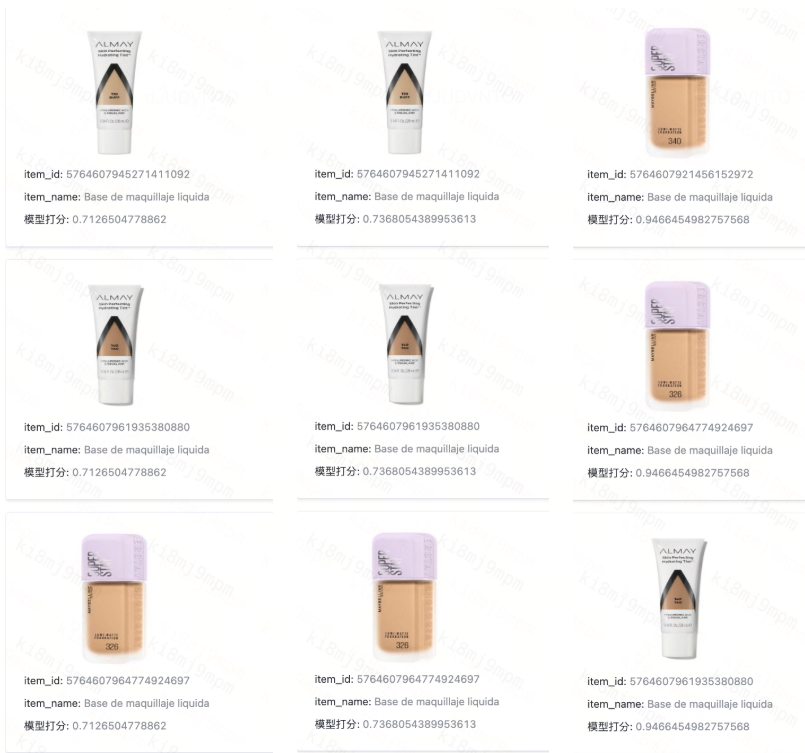
Figure : Les recherches pour « Liquid Foundation » fonctionnent tout aussi bien que les utilisateurs saisissent le terme anglais, le chinois « 液体妆前乳 » ou l’espagnol « Base de maquillaje líquida ».
Les requêtes produit complexes démontrent la compréhension contextuelle de la recherche vectorielle. Lorsque les utilisateurs recherchent « Redac PalancaPara WC Blanca » (un levier de chasse d’eau blanc), le système vectoriel fait correspondre précisément la requête malgré la terminologie technique composée, tandis que la recherche traditionnelle ne parvient pas à analyser la description produit en plusieurs mots.
Ces gains se traduisent par une expérience d’achat plus fluide, une satisfaction client plus élevée et un avantage concurrentiel définitif sur le marché de l’e-commerce de produits frais.
Feuille de route future : capacités de recherche de nouvelle génération
En s’appuyant sur cette base solide, DiDi et Milvus collaborent sur plusieurs capacités avancées pour la prochaine phase de développement.
La synchronisation du catalogue en temps réel réduira la latence entre les changements d’inventaire et les données consultables grâce à des mises à jour en streaming, garantissant que les utilisateurs ne voient jamais de produits qui ne sont pas réellement disponibles. L’intégration des signaux comportementaux fusionnera la similarité vectorielle avec l’historique utilisateur, les préférences et les signaux contextuels afin de fournir des recommandations hyper-personnalisées qui s’améliorent au fil du temps.
La recherche hybride avancée et le reclassement représentent peut-être le développement le plus enthousiasmant. Ce système combinera les indicateurs métier, notamment le prix, les notes, les promotions et les niveaux de stock, avec la pertinence sémantique afin de faire émerger des recommandations réellement optimales pour chaque acheteur individuel.
Le support multilingue amélioré élargira la couverture linguistique et améliorera la prise en charge des dialectes régionaux à mesure que DiDi pénètre de nouveaux marchés. L’optimisation dynamique des embeddings mettra en œuvre des mécanismes d’apprentissage continu pour améliorer la qualité des embeddings en fonction des schémas réels d’interaction des utilisateurs, créant ainsi un système de recherche qui devient de plus en plus intelligent à l’usage.
En innovant continuellement, DiDi redéfinit l’expérience de recherche de produits alimentaires, garantissant que chaque acheteur trouve exactement ce dont il a besoin, à chaque fois.
Conclusion
Le parcours de DiDi Food avec Milvus démontre que la recherche sémantique représente plus qu’une mise à niveau technique : c’est une réinvention fondamentale de la façon dont les utilisateurs interagissent avec de vastes catalogues de produits. En combinant une architecture de données réfléchie, des choix technologiques appropriés et une attention constante portée à l’expérience utilisateur, ils ont créé un système de recherche qui comprend véritablement l’intention à travers les langues et les cultures.
Les résultats valident cette approche : moins d’utilisateurs frustrés, davantage d’achats réussis et une expérience d’achat qui fonctionne quelle que soit la manière dont les clients choisissent d’exprimer leurs besoins. Pour les 2 millions d’utilisateurs mensuels de DiDi, cela signifie trouver systématiquement ce dont ils ont besoin, quand ils en ont besoin, dans la langue qui leur semble la plus naturelle.
Cette réussite illustre ce qui devient possible lorsque des entreprises innovantes adoptent la compréhension sémantique à grande échelle. Alors que DiDi continue son expansion en Amérique latine, son architecture de recherche propulsée par Milvus fournit une base robuste pour poursuivre l’innovation et améliorer la satisfaction des utilisateurs. La technologie fonctionne, les résultats commerciaux sont clairs, et l’amélioration de l’expérience utilisateur est tangible — exactement ce que devrait apporter une excellente ingénierie.
- À propos de DiDi Food
- Le défi de la recherche : quand Elasticsearch basé sur les mots-clés atteint ses limites
- La solution : créer un moteur de recherche sémantique avec Milvus
- Résultats de performance et impact réel
- Feuille de route future : capacités de recherche de nouvelle génération
- Conclusion
Contenu
Cas d'usage
Secteur d'activité
Commerce électronique
Technologie utilisée