




RAG multimodal au niveau local avec CLIP et Llama3
Avec la sortie récente de GPT-4o et de Gemini, la multimodalité a été un sujet brûlant ces derniers temps. L'année dernière, [Retrieval Augmented Generation] (https://zilliz.com/learn/Retrieval-Augmented-Generation) (RAG) a également occupé le devant de la scène, mais il était principalement axé sur le texte. Ce tutoriel vous montrera comment construire un système RAG multimodal.
En utilisant la RAG multimodale, vous n'êtes pas obligé d'utiliser uniquement du texte ; vous pouvez utiliser différents types de données tels que des images, du son, des vidéos et du texte, bien sûr. Il est également possible de renvoyer différents types de données ; ce n'est pas parce que vous utilisez du texte en entrée de votre système RAG que vous devez obligatoirement renvoyer du texte en sortie. C'est ce que nous montrerons au cours de ce tutoriel.
Conditions préalables
Avant de commencer à mettre en place les différents composants de notre tutoriel, assurez-vous que votre système dispose des éléments suivants :
Docker & Docker-Compose-Assurez-vous que Docker et Docker-Compose sont [installés] (https://docs.docker.com/compose/install/) sur votre système.
Milvus Standalone-Pour nos besoins, nous utiliserons l'efficace Milvus Standalone, qui est facilement géré via Docker Compose ; consultez notre documentation pour obtenir des [conseils] d'installation (https://milvus.io/docs/install_standalone-docker-compose.md).
Ollama-Installez Ollama sur votre système. Cela nous permettra d'utiliser Llama3 sur notre ordinateur portable. Visitez leur site web pour obtenir le dernier guide d'installation.
OpenAI CLIP
L'idée centrale du modèle CLIP (Contrastive Language-Image Pretraining) est de comprendre le lien entre une image et un texte. Il s'agit d'un modèle d'IA fondamental entraîné sur des paires texte-image. Il apprend ensuite à créer un point dans l'espace vectoriel pour le texte et les images. Dans cet espace, les descriptions textuelles similaires seront proches des images pertinentes et vice versa.
CLIP peut être utilisé pour différentes applications, notamment :
Recherche d'images : Imaginez la recherche d'images à l'aide d'une description textuelle ou la recherche de la légende parfaite correspondant à une image.
Apprentissage multimodal** : la capacité de CLIP à relier le texte et les images en fait un élément de base idéal pour des systèmes tels que RAG multimodal, qui traitent des informations sous différents formats.
Cela permet à notre système RAG de comprendre et de répondre à des requêtes qui peuvent impliquer à la fois du texte et des images.
Fig1 : Architecture de OpenAI CLIP] (https://assets.zilliz.com/Architecture_of_Open_AI_CLIP_765f6f1fc0.png)
Embeddings multimodaux
**En termes plus simples, les embeddings sont des représentations compressées de données. CLIP prend une image ou un texte en entrée et le transforme en un code numérique capturant ses principales caractéristiques.
La beauté de CLIP réside dans le fait qu'il fonctionne aussi bien pour les textes que pour les images. Vous pouvez lui donner une image et il générera un code qui capturera le contenu visuel. Mais vous pouvez également lui fournir du texte, et CLIP générera un embedding qui reflétera le sens du texte.
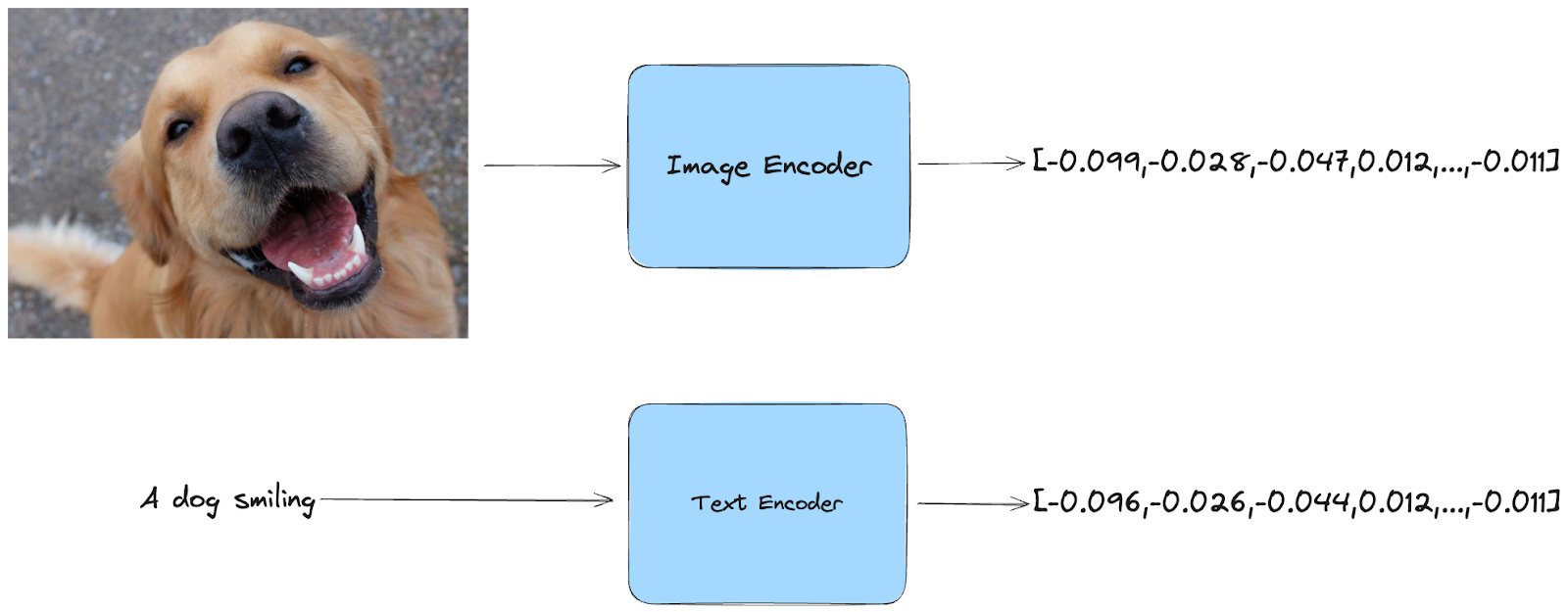 Multimodal Embeddings
Multimodal Embeddings
Si vous imaginiez une projection dans l'espace vectoriel, vous auriez des enregistrements avec des significations similaires proches les uns des autres. Par exemple, le texte "Un chien qui sourit" et l'image d'un chien qui semble sourire sont proches l'un de l'autre.
Fig2. Représentation dans un espace vectoriel](https://assets.zilliz.com/Representation_in_a_Vector_Space_e47a5a4373.png)
Construction d'un RAG multimodal
Nous utiliserons les données de Wikipedia, téléchargerons les données textuelles associées à ce que nous voulons apprendre davantage et ferons de même avec les images.
Nous allons générer des Embeddings avec le modèle CLIP ViT-B/32 et utiliser Llama3 comme LLM.
Nous stockons les embeddings dans Milvus, qui est conçu pour gérer les embeddings à grande échelle afin que nous puissions effectuer une recherche rapide et efficace.
LlamaIndex est utilisé comme moteur de requête en combinaison avec Milvus comme magasin de vecteurs.
L'ensemble du code est assez long, car nous devons parcourir Wikipédia, traiter le texte et les images, puis créer une application RAG. Cependant, il est entièrement disponible sur Github, donc vous devriez absolument y jeter un coup d'œil !
Une fois que vous l'aurez fait fonctionner, vous devriez être en mesure d'exécuter des requêtes similaires à celles qui suivent :
# https://en.wikipedia.org/wiki/Helsinki
query2 = "Quelles sont les attractions touristiques les plus populaires à Helsinki ?"
# générer des résultats de recherche d'images
image_query(query2)
# générer des résultats de recherche de texte
text_retrieval_results = text_query_engine.query(query2)
print("Résultats de la recherche de texte : \N" + str(text_retrieval_results))
Ce qui devrait donner quelque chose de similaire à
Parmi les attractions touristiques les plus populaires d'Helsinki, citons Suomenlinna (Sveaborg), une île forteresse à l'histoire riche, et le zoo de Korkeasaari, situé sur l'une des principales îles d'Helsinki. La ville compte également de nombreuses réserves naturelles, dont Vanhankaupunginselkä, qui est la plus grande réserve naturelle d'Helsinki.

Et avec cela, vous aurez une application RAG multimodale qui est capable de traiter des images ou du texte et qui peut également retourner des images ou du texte.
Vous pouvez accéder au code sur Github, poser des questions sur notre Discord, et nous donner une étoile sur Github.

Continuer à lire

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.