




Read AI escala la inteligencia conversacional con Milvus para millones de usuarios activos

Menos de 20-50 ms
latencia de recuperación para millones de usuarios mensuales
aceleración de 5×
en la búsqueda agéntica
A escala de millones
soporte para inquilinos activos
Experiencia de usuario mejorada
al impulsar un cambio de la búsqueda reactiva a la proactiva
We've got millions of monthly active users and all of the underlying data when we're trying to go find related conversations, find updates to an action item, find referenced documents...Milvus serves as the central repository and powers our information retrieval among billions of records.
Rob Williams
Resumen ejecutivo
Read AI necesitaba una base de datos vectorial de alto rendimiento para admitir la recuperación a escala empresarial desde fuentes de comunicación no estructuradas, incluidas reuniones, chats, correos electrónicos y bases de conocimiento internas. Al adoptar Milvus como la columna vertebral de su infraestructura de búsqueda semántica, Read AI pudo indexar y consultar embeddings ricos en narrativa a escala, lo que permitió una recuperación rápida y precisa en miles de millones de registros.
Latencia de recuperación inferior a 20-50 ms para millones de usuarios mensuales
Altamente escalable para gestionar millones de tenants activos
Importantes mejoras en la productividad de los desarrolladores
“Tenemos millones de usuarios activos mensuales y todos los datos subyacentes cuando intentamos encontrar conversaciones relacionadas, encontrar actualizaciones de un elemento de acción, encontrar documentos referenciados...Milvus sirve como repositorio central e impulsa nuestra recuperación de información entre miles de millones de registros.”--Rob Williams, cofundador y CTO de Read AI
Acerca de Read AI
Read AI es una empresa líder de IA de productividad que ayuda a millones de personas a dedicar más tiempo al trabajo que más importa. Inicialmente centrada en reducir la fatiga de las reuniones, la empresa ha evolucionado hasta convertirse en una plataforma de inteligencia full-stack que también ofrece próximos pasos predictivos, búsqueda empresarial y coaching en tiempo real que se integra sin problemas con herramientas de calendarios (Google Calendar, Outlook 365, Zoom Calendar), CRM (Salesforce, HubSpot), plataformas de colaboración (Jira, Confluence, Notion), aplicaciones de mensajería (Slack, Microsoft Teams), herramientas para tomar notas (Google Docs, OneNote), correo electrónico (Gmail, Outlook) y videoconferencias (Zoom, Google Meet, Microsoft Teams). Ingiera y contextualiza datos de estas fuentes, transformando interacciones pasivas en narrativas estructuradas, consultables y accionables.
Creada con una mentalidad orientada primero al consumidor, Read AI da soporte a millones de usuarios mediante un modelo de autoservicio, operando a verdadera escala de internet con miles de millones de eventos de conversación procesados en innumerables empresas.
El desafío técnico
Debido a su crecimiento vertiginoso, Read AI se enfrentó a un desafío fundamental para organizar y recuperar datos de comunicación no estructurados en una amplia variedad de fuentes, desde reuniones y chats hasta actualizaciones de CRM, calendarios, hilos de correo electrónico y tickets de soporte. Cada fuente contiene señales valiosas, pero vive en silos, carece de una estructura coherente y es difícil de buscar de manera eficaz. La expectativa: entregar resultados inteligentes y contextuales dentro de los 20 minutos posteriores a cualquier interacción.
Esto requería ingesta, transformación e indexación de datos casi en tiempo real en diversos formatos. Desde reuniones internas bien estructuradas hasta plataformas de terceros con datos escasos como Slack, Gmail y HubSpot. A medida que crecía el uso, Read AI necesitaba soportar miles de millones de registros en millones de tenants, miles de consultas por segundo y una latencia inferior a 20 - 50 ms. Las soluciones anteriores, incluidas tiendas creadas internamente y otras bases de datos vectoriales como Pinecone y Faiss, no lograron satisfacer estas demandas debido al deficiente soporte multitenant, capacidades de filtrado limitadas o falta de capacidad de respuesta de la comunidad.
La arquitectura de la solución con Milvus
La nueva arquitectura de Read AI está diseñada para gestionar una recuperación de alto rendimiento y baja latencia en diversas fuentes de comunicación como Slack, Zoom, correo electrónico y Salesforce. Estas entradas pasan por una capa de embedding y narración que transforma los datos sin procesar en narrativas estructuradas y representaciones sensibles al sentimiento. Todo se almacena en la base de datos vectorial Milvus, que sirve efectivamente como repositorio central de la información.
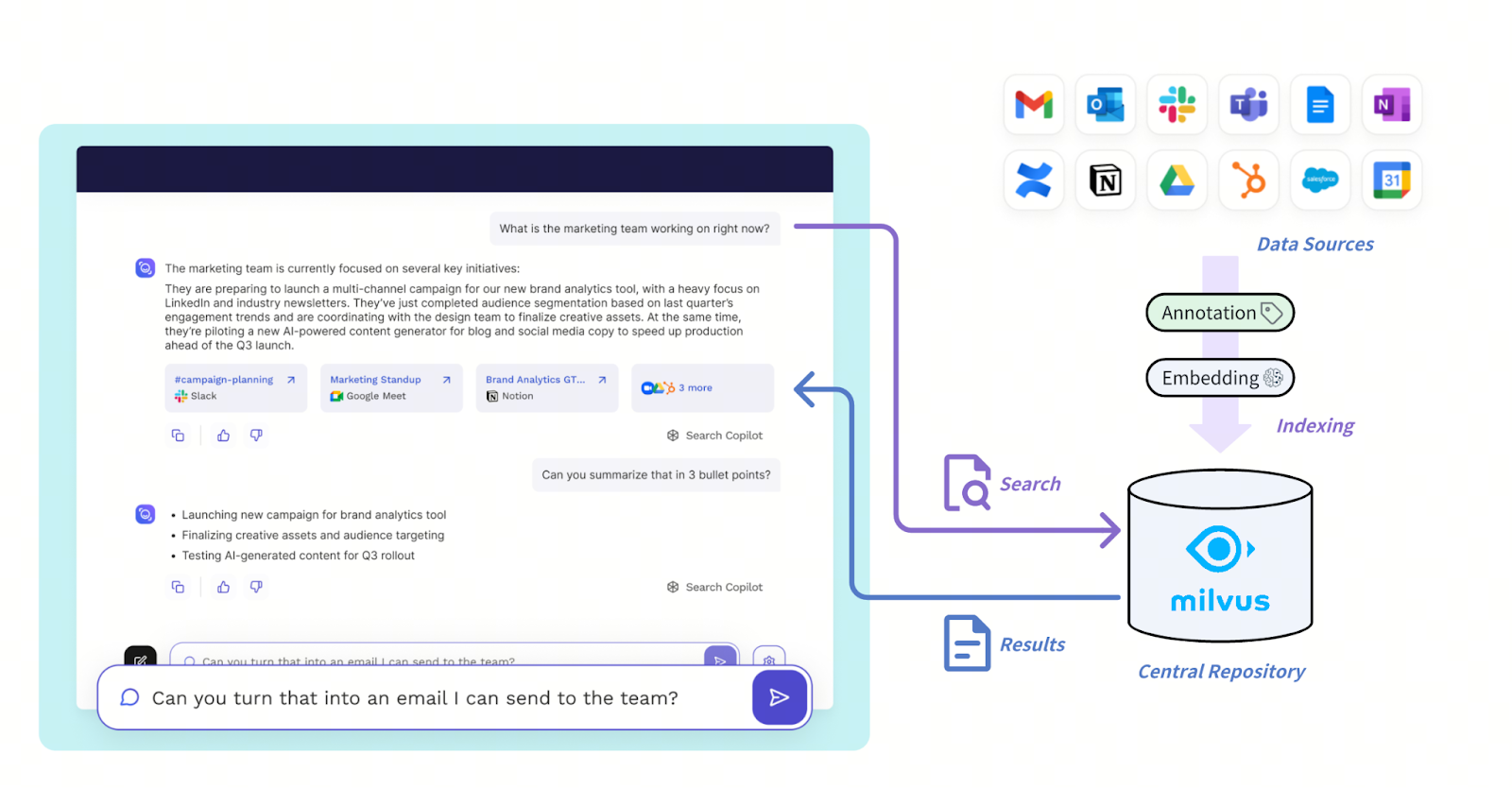 La arquitectura de la solución con Milvus
La arquitectura de la solución con Milvus
Figura: Cómo Mivus da soporte al sistema de Read AI
Read AI utiliza una búsqueda vectorial filtrada que combina la similitud vectorial con el filtrado basado en metadatos estructurados, por ejemplo, delimitando las consultas a reuniones individuales, empleados específicos o ventanas de tiempo, lo que permite una recuperación matizada como “llamadas de ventas con mayor desconexión” o “feedback positivo en reuniones individuales.” El filtrado optimizado de metadatos de Milvus es crucial para lograr una latencia inferior a 20-50 ms a esta escala.
"Milvus nos ofrece una capa de almacenamiento consciente de la narrativa — no solo embeddings de texto, sino una búsqueda completa consciente del contexto." — Rob Williams, Co-Founder and CTO at Read AI
Gracias al soporte nativo de multi-tenancy en Milvus, Read AI despliega un único clúster de Milvus para atender de manera eficiente a millones de tenants. Las consultas se orquestan a través de frameworks internos de agentes que analizan la intención de búsqueda y enrutan las solicitudes hacia Milvus, y luego posprocesan los resultados para entregarlos mediante interfaces de chat, resúmenes o alertas. Esta arquitectura brinda a Read AI la escalabilidad y flexibilidad para unificar tipos de contenido dispares mientras mantiene la velocidad y precisión, que son críticas para la recuperación en tiempo real y el análisis retrospectivo.
Evaluación técnica y proceso de decisión
Antes de adoptar Milvus, el equipo de Read AI evaluó varias alternativas. FAISS se descartó debido a su falta de multi-tenancy integrada y sus capacidades de filtrado limitadas. Pinecone no ofrecía la flexibilidad necesaria para soportar el patrón de búsqueda y la escala de Read AI. También se consideró una solución completamente self-hosted y desarrollada internamente, pero no podía cumplir con los requisitos de escalabilidad y madurez de su caso de uso. Milvus destacó por varios factores clave:
La capacidad de escalar a millones de usuarios y miles de millones de registros
Latencia constante inferior a 20-50 ms en grandes colecciones vectoriales
Soporte para flujos de trabajo de búsqueda híbrida
Aislamiento a nivel de tenant
La experiencia del desarrollador fue otro factor decisivo, con documentación clara, maintainers receptivos y soporte de ingeniería práctico, especialmente durante su prueba de concepto. La fase de PoC demostró una rápida respuesta en cargas de trabajo de prueba y proporcionó asistencia de depuración en tiempo real por parte del equipo de Milvus, lo que dio a Read AI la confianza para pasar a producción.
Resultados y beneficios de elegir Milvus
Desde el despliegue de Milvus y junto con el lanzamiento por parte de la compañía de su herramienta de búsqueda empresarial Search Copilot, Read AI ha logrado una aceleración de 5× en la búsqueda agentic a través de diversas fuentes de datos, manteniendo una latencia de recuperación constante de alrededor de 20- 50 ms, incluso al gestionar consultas con filtros complejos. La plataforma incorporó sin problemas millones de cuentas de usuarios individuales en un clúster gigante sin interrupciones, demostrando la robustez de la arquitectura distribuida de Milvus y su capacidad de multi-tenancy.
Milvus impulsa una capa de búsqueda unificada en todos los canales de comunicación—reuniones, chat, correo electrónico y CRM. El escalado elástico simplifica la operación para gestionar cohortes empresariales o picos de tráfico. Funciones como la importación masiva conducen a una experiencia fluida al incorporar grandes cantidades de datos históricos cuando nuevas empresas se registran en el servicio.
Más importante aún, Milvus impulsa un cambio de la búsqueda reactiva a la proactiva: sacando a la superficie insights relevantes, elementos de acción y riesgos antes de que los usuarios siquiera pregunten, gracias a la búsqueda vectorial de baja latencia sobre contextos dinámicos y multimodales. Esta capacidad no solo mejora la experiencia del usuario, sino que también desbloquea nuevas oportunidades de negocio a medida que Read AI continúa enfocándose en expandir la plataforma con avances continuos en recomendaciones predictivas y próximos pasos.
"Lo que queríamos era llevar la inteligencia al usuario antes de que siquiera preguntara. Milvus es lo que hizo eso viable." —Rob Williams, Co-Founder and CTO at Read AI
Estos logros técnicos se traducen directamente en valor de negocio: los usuarios del nivel gratuito reciben insights significativos en cuestión de minutos, impulsando la retención, mientras que los clientes empresariales se benefician de una recuperación de conocimiento más profunda y contexto a largo plazo, mejorando la confianza del usuario y respaldando oportunidades de upsell premium.
Perspectivas para desarrolladores e ingeniería
Lecciones de la implementación:
La anotación estructurada puede impulsar resultados posteriores de LLM más enriquecidos
La búsqueda vectorial debe mantener su velocidad, incluso con filtrado de metadatos estructurados, para estar a la altura de la experiencia de búsqueda del usuario
El aislamiento multiinquilino y el escalado dinámico no son negociables a escala de consumo
El equipo realiza experimentos continuos, haciendo seguimiento del rendimiento de las consultas, la satisfacción del usuario y las métricas de comportamiento para perfeccionar continuamente cómo los agentes buscan, filtran y clasifican los resultados.
Read AI procesa datos conversacionales no solo con modelos de embeddings, sino también con una capa de narración única. Esta abstracción semántica va más allá de las transcripciones para capturar el tono, la intención y eventos clave como el avance de un acuerdo o la caída del engagement. Como resultado, los usuarios pueden buscar narrativas en lenguaje natural, como "quién estuvo desconectado durante la demo", en lugar de limitarse a hacer coincidir palabras clave.
Hoja de ruta
De cara al futuro, Read AI se centra en mejorar cómo equilibra las cargas de trabajo en tiempo real y offline, con planes para crear una orquestación más dinámica entre los datos de streaming en vivo y el almacenamiento a más largo plazo. Están explorando el uso del próximo Vector Lake de Milvus para reducir los costos de búsqueda desplazando las consultas offline con expectativas de latencia más flexibles a una capa de estilo almacén respaldada por almacenamiento de objetos.
Otra área clave de desarrollo es la detección automatizada de brechas de conocimiento: identificar cuándo falta información crítica o cuándo está desconectada, y presentar proactivamente insights a los usuarios antes de que los pidan. Todas estas mejoras respaldan la visión a largo plazo de Read AI: construir un “motor de acción” para la empresa: una plataforma impulsada por IA, siempre activa y consciente del contexto, que empodere de forma inteligente a los trabajadores del conocimiento en todos los canales de comunicación.
Al almacenar el contexto conversacional y los insights históricos en Milvus, Read AI amplía la disponibilidad del conocimiento institucional, mostrando información crítica incluso cuando el participante original está desconectado o ya no está en la empresa.
Conclusión
El recorrido de Read AI desde una herramienta de análisis de reuniones hasta una plataforma de inteligencia a gran escala para las masas requería una infraestructura capaz de manejar una escala masiva, datos heterogéneos y demandas de consulta complejas en tiempo real. Milvus demostró ser la elección correcta, no solo por su rendimiento bruto y escalabilidad, sino por su flexibilidad para admitir embeddings anotados, filtrado de metadatos y aislamiento multiinquilino.
Con Milvus como base de su infraestructura de búsqueda vectorial, Read AI ofrece resultados y recomendaciones rápidos, fiables y profundamente contextuales a millones de usuarios. A medida que avanzan hacia la creación de un motor de acción inteligente y siempre activo para la empresa, Milvus continúa respaldando su necesidad de eficiencia de costos, flexibilidad arquitectónica y escala preparada para el futuro, demostrando que una base de datos vectorial bien diseñada es más que solo almacenamiento; es la columna vertebral de la comprensión moderna de la información.
What we wanted was to push intelligence to the user before they even asked. Milvus is what made that viable.
Rob Williams