




Las 10 principales técnicas de ingeniería de contexto que debes conocer para RAG en producción
Cuando construimos por primera vez una demo de RAG o de agente, las cosas suelen funcionar bien. Con un conjunto de datos pequeño, unos pocos prompts y una recuperación simple, a menudo podemos tener un prototipo funcionando en unas pocas horas.
El verdadero desafío aparece cuando intentamos ejecutar el sistema en producción. A medida que crece el uso, los problemas aparecen rápidamente. La recuperación se vuelve más lenta, las respuestas se vuelven menos fiables, la latencia aumenta y los costes suben. Lo que funcionaba en una pequeña demo a menudo se rompe cuando entran en juego datos reales, usuarios reales y contextos más largos.
En este punto, normalmente nos damos cuenta de que el problema no es solo el modelo. También tiene que ver con cómo se prepara el contexto y se pasa al modelo. Aquí es donde entra en juego la ingeniería de contexto. Se centra en recuperar, organizar, refinar y gestionar la información que un modelo de lenguaje utiliza para generar respuestas.
En este artículo, explicamos cómo funciona la ingeniería de contexto en la práctica. Analizamos enfoques recientes para construir contexto, procesarlo de forma eficiente y gestionarlo a lo largo del tiempo. Estas técnicas ayudan a convertir demos simples en sistemas que pueden ejecutarse de forma fiable en producción.
Nota: Este artículo se basa principalmente en el paper https://arxiv.org/html/2507.13334v1.
¿Qué es la ingeniería de contexto?
La ingeniería de contexto se centra en reunir la información que un modelo de lenguaje grande necesita para responder bien a una pregunta. Esta información no se limita al prompt. También incluye la consulta del usuario, los documentos recuperados, el historial de conversación y otros datos relevantes. El objetivo es mejorar la precisión, reducir el tiempo de respuesta y controlar los costes.
Este trabajo se realiza principalmente de forma automática mediante algoritmos. La ingeniería de contexto combina la ingeniería de prompts, la generación aumentada por recuperación (RAG) y las técnicas multiagente en un solo sistema, en lugar de usarlas por separado.
En la práctica, una configuración de ingeniería de contexto tiene dos partes. La primera consiste en componentes fundamentales que gestionan la recuperación, el procesamiento y la orquestación de datos. La segunda capa está formada por sistemas complejos que combinan estos componentes en aplicaciones completas. Los equipos pueden mezclar y reutilizar estas partes para adaptarse a diferentes escenarios de producción.
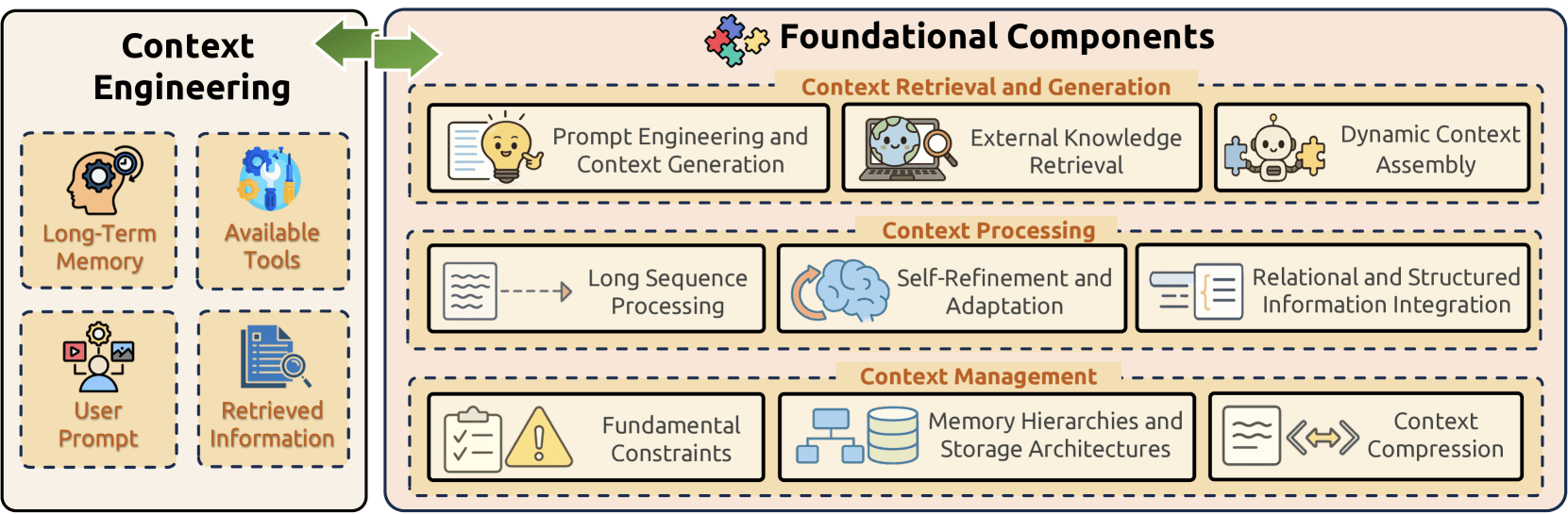
Componentes fundamentales
La ingeniería de contexto se basa en tres componentes fundamentales que, en conjunto, abordan los desafíos centrales de la gestión de información en los modelos de lenguaje grandes:
- Recuperación y generación de contexto obtiene información contextual adecuada mediante ingeniería de prompts, recuperación de conocimiento externo y ensamblaje dinámico de contexto;
- Procesamiento de contexto transforma y optimiza la información adquirida mediante procesamiento de secuencias largas, mecanismos de autorrefinamiento e integración de datos estructurados;
- Gestión de contexto aborda la organización y utilización eficiente de la información contextual al tratar restricciones fundamentales, implementar jerarquías de memoria sofisticadas y desarrollar técnicas de compresión.
Sistemas complejos en la práctica
Sobre estos componentes fundamentales, la ingeniería de contexto se aplica mediante varios tipos comunes de sistemas complejos.
La generación aumentada por recuperación (RAG) permite que un modelo busque información en una base de conocimiento antes de responder una pregunta. Esto ayuda a garantizar que la respuesta se base en datos reales y actuales en lugar de que el modelo adivine. En la práctica, RAG puede construirse como pipelines modulares simples, impulsados por agentes que controlan la recuperación, o combinarse con grafos de conocimiento para un contexto más rico.
Los sistemas de memoria permiten que los modelos hagan seguimiento de información a lo largo de las interacciones. La memoria a corto plazo conserva detalles de la conversación actual, mientras que la memoria a largo plazo almacena conversaciones pasadas y conocimiento aprendido. Esto hace que las conversaciones de varios turnos sean más consistentes y ayuda al sistema a mejorar con el tiempo.
El razonamiento integrado con herramientas permite que los modelos usen herramientas externas como calculadoras, motores de búsqueda o APIs en lugar de depender únicamente del razonamiento textual. Una parte importante de esta configuración es insertar los resultados de las herramientas de nuevo en el contexto en el momento adecuado para que el modelo pueda usarlos de forma eficaz.
Los sistemas multiagente utilizan múltiples modelos que trabajan juntos para gestionar tareas complejas. Cada agente tiene un rol específico, y el sistema coordina cómo se comunican, comparten información y se mantienen sincronizados para producir un resultado coherente.
Procesamiento del contexto
Anteriormente, presentamos las tres partes principales de la ingeniería de contexto: recuperación y generación de contexto, procesamiento del contexto y gestión del contexto. Estas forman los bloques básicos de construcción de un sistema de contexto práctico.
El procesamiento del contexto es especialmente importante. Toma la información recuperada en bruto y la limpia, la remodela y la organiza para que el modelo pueda entenderla y usarla de manera más eficiente.
En esta sección, analizamos cómo se realiza el procesamiento del contexto en sistemas reales y qué enfoques se utilizan comúnmente.
Procesamiento de contexto largo
Procesar contextos muy largos es costoso porque los modelos transformer usan autoatención, que escala mal a medida que aumenta la longitud de la entrada. A medida que la secuencia se hace más larga, el cálculo y el uso de memoria aumentan rápidamente, lo que crea cuellos de botella reales en los sistemas de producción.
Por ejemplo, ampliar la longitud de entrada de Mistral-7B de 4K a 128K tokens aumenta el coste computacional aproximadamente 122×. El uso de memoria también aumenta de forma pronunciada tanto durante el prellenado como durante la decodificación. En la práctica, modelos como Llama 3.1 8B pueden requerir hasta 16 GB de memoria para una sola solicitud de 128K tokens.
Para sortear estos límites, los investigadores utilizan principalmente tres enfoques.
Uno es construir nuevas arquitecturas de modelos, como Mamba, que sean más baratas de ejecutar por diseño. Otro es usar técnicas como la interpolación posicional para permitir que los modelos existentes manejen entradas mucho más largas. El tercer enfoque mejora cómo se realiza el cálculo, evitando trabajo redundante y usando la memoria de manera más eficiente, de modo que el procesamiento de contextos largos sea más rápido y use menos recursos.
(1) Innovaciones arquitectónicas para contexto largo
Para abordar el coste cuadrático de los Transformers, los investigadores han desarrollado nuevas arquitecturas de modelos que hacen que el procesamiento de secuencias largas sea más barato y eficiente.
- Modelos de espacio de estados (SSMs) mantienen una complejidad computacional lineal y requisitos de memoria constantes mediante estados ocultos de tamaño fijo, con modelos como Mamba que ofrecen mecanismos eficientes de cálculo recurrente que escalan de forma más eficaz que los transformers tradicionales.
- La atención dilatada en enfoques como LongNet emplea campos de atención que se expanden exponencialmente a medida que crece la distancia entre tokens, logrando una complejidad computacional lineal mientras mantiene una dependencia logarítmica entre tokens, lo que hace posible procesar secuencias de más de mil millones de tokens.
- Las redes neuronales Toeplitz (TNNs) modelan secuencias con matrices Toeplitz con posición relativa codificada, reduciendo la complejidad espacio-temporal a log-lineal y permitiendo la extrapolación de 512 tokens de entrenamiento a 14,000 tokens de inferencia.
- Los mecanismos de atención lineal reducen la complejidad de O(N²) a O(N) al expresar la autoatención como productos escalares lineales de mapas de características de núcleo, logrando una aceleración de hasta 4000× al procesar secuencias muy largas.
Enfoques alternativos como los LLMs sin atención rompen las barreras cuadráticas al emplear transformers de memoria recursiva y otras innovaciones arquitectónicas.
(2) Interpolación posicional y extensión del contexto
Las técnicas de interpolación posicional permiten que los modelos procesen secuencias más allá de las limitaciones de la ventana de contexto original al reescalar inteligentemente los índices de posición en lugar de extrapolar a posiciones no vistas.
- Los enfoques de Neural Tangent Kernel (NTK) proporcionan marcos con fundamento matemático para la extensión del contexto, con YaRN (Yet another RoPE-based Interpolation method) combinando la interpolación NTK con la interpolación lineal y la corrección de la distribución de atención.
- Enfoques de dos etapas: LongRoPE logra ventanas de contexto de 2048K tokens mediante enfoques de dos etapas: primero ajustando modelos a una longitud de 256K, luego realizando interpolación posicional para alcanzar la longitud máxima de contexto.
- Position Sequence Tuning (PoSE) demuestra impresionantes extensiones de longitud de secuencia de hasta 128K tokens al combinar múltiples estrategias de interpolación posicional.
- Las técnicas de Self-Extend permiten a los LLM procesar contextos largos sin ajuste fino mediante el empleo de estrategias de atención de dos niveles —atención agrupada y atención vecina— para capturar dependencias entre tokens distantes y adyacentes.
(3) Técnicas de optimización para un procesamiento eficiente
Sin cambiar la arquitectura central del modelo, los investigadores también han desarrollado una serie de técnicas de optimización para hacer que el procesamiento de contextos largos sea más eficiente.
Grouped-Query Attention (GQA) divide las cabezas de consulta en grupos que comparten cabezas de clave y valor, logrando un equilibrio entre la atención multi-consulta y la atención multi-cabeza, al tiempo que reduce los requisitos de memoria durante la decodificación.
FlashAttention aprovecha la jerarquía asimétrica de memoria de la GPU para lograr un escalado lineal de memoria en lugar de requisitos cuadráticos, con FlashAttention-2 proporcionando aproximadamente el doble de velocidad mediante la reducción de operaciones que no son multiplicaciones matriciales y una distribución del trabajo optimizada.
Ring Attention con Blockwise Transformers permite manejar secuencias extremadamente largas distribuyendo la computación entre múltiples dispositivos, aprovechando la computación por bloques mientras solapa la comunicación con el cálculo de la atención.
Las técnicas de atención dispersa incluyen Shifted sparse attention (S²-Attn) en LongLoRA y SinkLoRA con SF-Attn, que logran el 92% de la mejora de perplejidad de la atención completa con ahorros significativos de computación.
La gestión de memoria y compresión de contexto reducen el coste de las entradas largas. Rolling Buffer Cache limita la ventana de atención para reducir la memoria de la caché KV, mientras que StreamingLLM admite secuencias largas manteniendo solo tokens clave y contexto reciente. Otros métodos como Infini-attention y H2O mejoran la eficiencia mediante memoria compresiva y una expulsión de caché más inteligente.
Autorrefinamiento y adaptación contextuales
El autorrefinamiento permite a los LLM mejorar las salidas mediante mecanismos de retroalimentación cíclicos que reflejan los procesos de revisión humanos, aprovechando la autoevaluación a través de la autointeracción conversacional mediante ingeniería de prompts, distinta de los enfoques de aprendizaje por refuerzo.
La idea es simple: para tareas complejas, es más fácil escribir una primera versión y luego corregirla que acertar con todo de una vez. Cuando los modelos aprenden a revisar su propio trabajo y mejorarlo paso a paso, rinden mejor en razonamiento, escritura de código y tareas creativas, y se adaptan con mayor facilidad a nuevas situaciones.
(1) Marcos fundamentales de autorrefinamiento
- El marco Self-Refine utiliza el mismo modelo como generador, proveedor de retroalimentación y refinador, demostrando que identificar y corregir errores suele ser más fácil que producir soluciones iniciales perfectas.
- Reflexion mantiene texto reflexivo en búferes de memoria episódica para la toma de decisiones futura mediante retroalimentación lingüística, mientras que la guía estructurada resulta esencial, ya que los prompts simplistas a menudo no permiten una autocorrección fiable.
- El marco N-CRITICS implementa una evaluación basada en ensambles en la que las salidas iniciales son evaluadas tanto por los LLM generadores como por otros modelos, con retroalimentación compilada que guía el refinamiento hasta que se cumplen los criterios de detención específicos de la tarea.
(2) Metaaprendizaje y evolución autónoma
En una etapa más avanzada, el autorrefinamiento del contexto se centra en el metaaprendizaje y la mejora autónoma. El objetivo es ayudar al modelo no solo a resolver tareas, sino también a aprender cómo aprender mejor con el tiempo.
SELF enseña metahabilidades a los LLM (autorretroalimentación, autorrefinamiento) con ejemplos limitados, y luego hace que el modelo se autoevolucione continuamente generando y filtrando sus propios datos de entrenamiento. Los mecanismos de autorrecompensa permiten que los modelos mejoren de forma autónoma mediante un autojuicio iterativo, en el que un único modelo adopta roles duales como ejecutor y juez, maximizando las recompensas que se asigna a sí mismo.
El marco Creator amplía este paradigma al permitir que los LLM creen y utilicen sus propias herramientas mediante un proceso de cuatro módulos que abarca creación, toma de decisiones, ejecución y reconocimiento.
El marco Self-Developing representa el enfoque más autónomo, ya que permite que los LLM descubran, implementen y refinen sus propios algoritmos de mejora mediante ciclos iterativos que generan candidatos algorítmicos como código ejecutable.
Contexto multimodal
Los modelos de lenguaje grandes multimodales (MLLM) van más allá del texto al trabajar con entradas como imágenes, audio y datos 3D. Combinan estos diferentes tipos de información en un único contexto sobre el que el modelo puede razonar.
Esto hace posibles aplicaciones más avanzadas, pero también trae nuevos desafíos, como integrar diferentes modalidades, razonar entre ellas y manejar entradas largas y complejas.
(1) Integración de contexto multimodal
La integración de contexto es el núcleo del procesamiento de contexto multimodal. Su objetivo es combinar información de diferentes modalidades, como imágenes, texto y audio, en una única representación con la que un modelo pueda razonar.
Un enfoque básico convierte las imágenes en tokens usando codificadores como CLIP y luego las añade a los tokens de texto antes de enviar todo al modelo de lenguaje. Esto es fácil de implementar, pero las diferentes modalidades a menudo permanecen conectadas de forma laxa.
Los métodos más avanzados mejoran la integración. La atención intermodal permite que el modelo aprenda relaciones directas entre tokens visuales y de texto dentro del modelo, lo cual es importante para tareas como la edición de imágenes y el razonamiento visual.
Para escalar a entradas largas o complejas, los diseños jerárquicos procesan cada modalidad por etapas. Algunos sistemas también fusionan información de múltiples imágenes o entradas antes de pasarlas al modelo, en lugar de manejar cada una por separado.
Otros trabajos evitan adaptar modelos solo de texto por completo al entrenar con datos multimodales y texto juntos desde el principio. El razonamiento intermodal se basa en esto, exigiendo que el modelo entienda no solo cada modalidad por sí sola, sino también el significado que surge cuando se combinan, como el sarcasmo expresado tanto mediante una imagen como mediante texto.
(2) Codificadores multimodales externos y módulos de alineación
La integración de contexto multimodal se basa en dos partes principales: codificadores multimodales externos y los módulos de alineación que los conectan con el modelo de lenguaje.
En la mayoría de los sistemas actuales, cada tipo de dato es manejado por un codificador dedicado. Por ejemplo, las imágenes son procesadas por modelos como CLIP, y el audio es manejado por modelos como CLAP. Estos codificadores convierten entradas sin procesar, como píxeles u ondas sonoras, en vectores de características.
Luego, los módulos de alineación convierten estas características al espacio de incrustaciones del modelo de lenguaje para que puedan trabajar junto con los tokens de texto. Algunos sistemas utilizan mapeos simples como MLP, mientras que otros usan Q-Former, que selecciona las características visuales más relevantes para el texto mediante tokens de consulta aprendibles.
Esta configuración modular hace que los sistemas sean más fáciles de mantener. Los codificadores pueden actualizarse o sustituirse sin volver a entrenar todo el modelo de lenguaje, lo cual es importante para el despliegue en el mundo real.
Contexto relacional y estructurado
Los modelos de lenguaje grandes enfrentan restricciones fundamentales al procesar datos relacionales y estructurados, incluidas tablas, bases de datos y grafos de conocimiento, debido a los requisitos de entrada basados en texto y a las limitaciones de la arquitectura secuencial.
La linealización a menudo no logra preservar relaciones complejas y propiedades estructurales, y el rendimiento se degrada cuando la información está dispersa a lo largo de los contextos.
Para resolver este problema, los investigadores han buscado formas de representar datos estructurados en una forma que los modelos de lenguaje puedan utilizar. El objetivo es ayudar a los modelos a rendir mejor en tareas que implican razonamiento complejo y verificación de hechos.
(1) Embeddings de grafos de conocimiento e integración neuronal
Las estrategias avanzadas de codificación abordan las limitaciones estructurales mediante embeddings de grafos de conocimiento que transforman entidades y relaciones en vectores numéricos, lo que permite un procesamiento eficiente dentro de las arquitecturas de modelos de lenguaje.
Las redes neuronales de grafos capturan relaciones complejas entre entidades, lo que facilita el razonamiento de varios saltos a través de estructuras de grafos de conocimiento mediante arquitecturas especializadas como GraphFormers, que anidan componentes GNN junto con bloques transformer.
(2) Verbalización
Un enfoque común consiste en convertir datos estructurados —como grafos de conocimiento, tablas o registros de bases de datos— en texto en lenguaje natural, de modo que puedan ser utilizados directamente por los modelos de lenguaje existentes sin cambiar su arquitectura. Otros métodos reorganizan el texto de entrada en capas estructuradas basadas en relaciones lingüísticas, o extraen información clave y la representan explícitamente como grafos, tablas o esquemas relacionales.
En algunos casos, representar datos estructurados utilizando lenguajes de programación funciona mejor que el lenguaje natural. Por ejemplo, usar código Python para grafos de conocimiento o SQL para bases de datos a menudo conduce a un mejor rendimiento en tareas de razonamiento complejo, porque estos formatos preservan la estructura con mayor claridad. También existen enfoques eficientes en recursos que utilizan representaciones matriciales compactas para manejar datos estructurados con menos parámetros manteniendo un buen rendimiento.
(3) Arquitecturas híbridas
Para manejar datos estructurados con relaciones complejas, como tablas y grafos de conocimiento, los investigadores han explorado arquitecturas híbridas que combinan grandes modelos de lenguaje con componentes diseñados para datos estructurados como grafos, como las redes neuronales de grafos.
Se utilizan varios enfoques prácticos. GraphToken hace explícitas las relaciones añadiendo tokens especiales, lo que ayuda a los modelos a razonar sobre grafos. Heterformer procesa texto y estructura de grafo juntos en un solo marco, conservando la información de relaciones mientras controla el coste computacional.
Otros métodos integran el conocimiento de distintas formas. K-BERT añade información de grafos de conocimiento durante el entrenamiento para que el modelo aprenda estas relaciones por adelantado. KAPING recupera conocimiento relevante en el momento de la inferencia, sin reentrenamiento. Diseños más avanzados utilizan adaptadores y atención para fusionar la información de grafos directamente en el modelo, lo que conduce a una integración más estrecha.
Conclusión
La ingeniería de contexto ofrece una forma útil de entender cómo funcionan los sistemas LLM en producción. En general, implica tres procesos principales: recuperación y generación de contexto, procesamiento de contexto y gestión de contexto. En conjunto, estos pasos determinan cómo se recopila, prepara y pasa la información al modelo.
Entre ellos, el procesamiento de contexto es especialmente importante porque decide cómo se limpia, organiza y comprime la información recuperada antes de llegar al modelo. Debido a las limitaciones de espacio, este artículo se centró principalmente en esta parte y revisó varios enfoques utilizados en sistemas reales. La recuperación y la gestión de contexto también son áreas importantes y pueden explorarse más a fondo en futuras discusiones.
Si estás creando sistemas RAG o de agentes y te encuentras con problemas en producción relacionados con el contexto, el coste o la latencia, únete a nuestro canal de Slack para debatir sobre ingeniería de contexto con otros ingenieros. También puedes reservar una breve sesión individual para obtener orientación práctica sobre cómo pasar de demos a sistemas listos para producción a través de Milvus Office Hours.
Sigue leyendo

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
AWS S3 Vectors aims for 90% cost savings for vector storage. But will it kill vectordbs like Milvus? A deep dive into costs, limits, and the future of tiered storage.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.