




Read AI scala l'intelligenza conversazionale con Milvus per milioni di utenti attivi

Sotto i 20-50 ms
latenza di recupero per milioni di utenti mensili
Velocità 5×
nella ricerca agentica
Su scala milionaria
supporto per tenant attivi
Esperienza utente migliorata
alimentando il passaggio da una ricerca reattiva a una proattiva
We've got millions of monthly active users and all of the underlying data when we're trying to go find related conversations, find updates to an action item, find referenced documents...Milvus serves as the central repository and powers our information retrieval among billions of records.
Rob Williams
Sintesi esecutiva
Read AI aveva bisogno di un database vettoriale ad alte prestazioni per supportare il recupero su scala enterprise da fonti di comunicazione non strutturate, tra cui riunioni, chat, email e basi di conoscenza interne. Adottando Milvus come spina dorsale della propria infrastruttura di ricerca semantica, Read AI è stata in grado di indicizzare e interrogare embedding ricchi di narrazione su larga scala, consentendo un recupero rapido e accurato su miliardi di record.
Latenza di recupero inferiore a 20-50 ms per milioni di utenti mensili
Altamente scalabile per gestire milioni di tenant attivi
Importanti miglioramenti nella produttività degli sviluppatori
“Abbiamo milioni di utenti attivi mensili e tutti i dati sottostanti quando cerchiamo di trovare conversazioni correlate, trovare aggiornamenti a un elemento d’azione, trovare documenti citati... Milvus funge da repository centrale e alimenta il nostro recupero delle informazioni tra miliardi di record.”--Rob Williams, Co-Founder e CTO di Read AI
Informazioni su Read AI
Read AI è un’azienda leader nell’AI per la produttività che aiuta milioni di persone a dedicare più tempo al lavoro che conta di più. Inizialmente focalizzata sulla riduzione della stanchezza da riunioni, l’azienda si è evoluta in una piattaforma di intelligence full-stack che offre anche prossimi passi predittivi, ricerca enterprise e coaching in tempo reale, integrandosi perfettamente con strumenti su calendari (Google Calendar, Outlook 365, Zoom Calendar), CRM (Salesforce, HubSpot), piattaforme di collaborazione (Jira, Confluence, Notion), app di messaggistica (Slack, Microsoft Teams), strumenti per prendere appunti (Google Docs, OneNote), email (Gmail, Outlook) e videoconferenze (Zoom, Google Meet, Microsoft Teams). Ingerisce e contestualizza dati da queste fonti, trasformando interazioni passive in narrazioni strutturate, interrogabili e azionabili.
Costruita con una mentalità consumer-first, Read AI supporta milioni di utenti tramite un modello self-service, operando su vera scala internet con miliardi di eventi conversazionali elaborati in innumerevoli aziende.
La sfida tecnica
A causa della sua crescita vertiginosa, Read AI ha dovuto affrontare una sfida fondamentale nell’organizzare e recuperare dati di comunicazione non strutturati da un’ampia gamma di fonti: da riunioni e chat ad aggiornamenti CRM, calendari, thread email e ticket di supporto. Ogni fonte contiene segnali preziosi ma vive in silos, manca di una struttura coerente ed è difficile da cercare in modo efficace. L’aspettativa: fornire output intelligenti e contestuali entro 20 minuti da qualsiasi interazione.
Ciò richiedeva ingestione, trasformazione e indicizzazione dei dati quasi in tempo reale su formati diversi. Da riunioni interne ben strutturate a piattaforme di terze parti sparse come Slack, Gmail e HubSpot. Con l’aumentare dell’utilizzo, Read AI doveva supportare miliardi di record su milioni di tenant, migliaia di query al secondo e una latenza inferiore a 20 - 50 ms. Le soluzioni precedenti, inclusi archivi costruiti internamente e altri database vettoriali come Pinecone e Faiss, non sono riuscite a soddisfare queste esigenze a causa dello scarso supporto multi-tenant, delle capacità di filtraggio limitate o della mancanza di reattività della community.
L’architettura della soluzione con Milvus
La nuova architettura di Read AI è progettata per gestire il recupero ad alto throughput e bassa latenza su diverse fonti di comunicazione come Slack, Zoom, email e Salesforce. Questi input passano attraverso un livello di embedding e narrazione che trasforma i dati grezzi in narrazioni strutturate e rappresentazioni sensibili al sentiment. Tutto è archiviato nel database vettoriale Milvus, che funge di fatto da repository centrale per le informazioni.
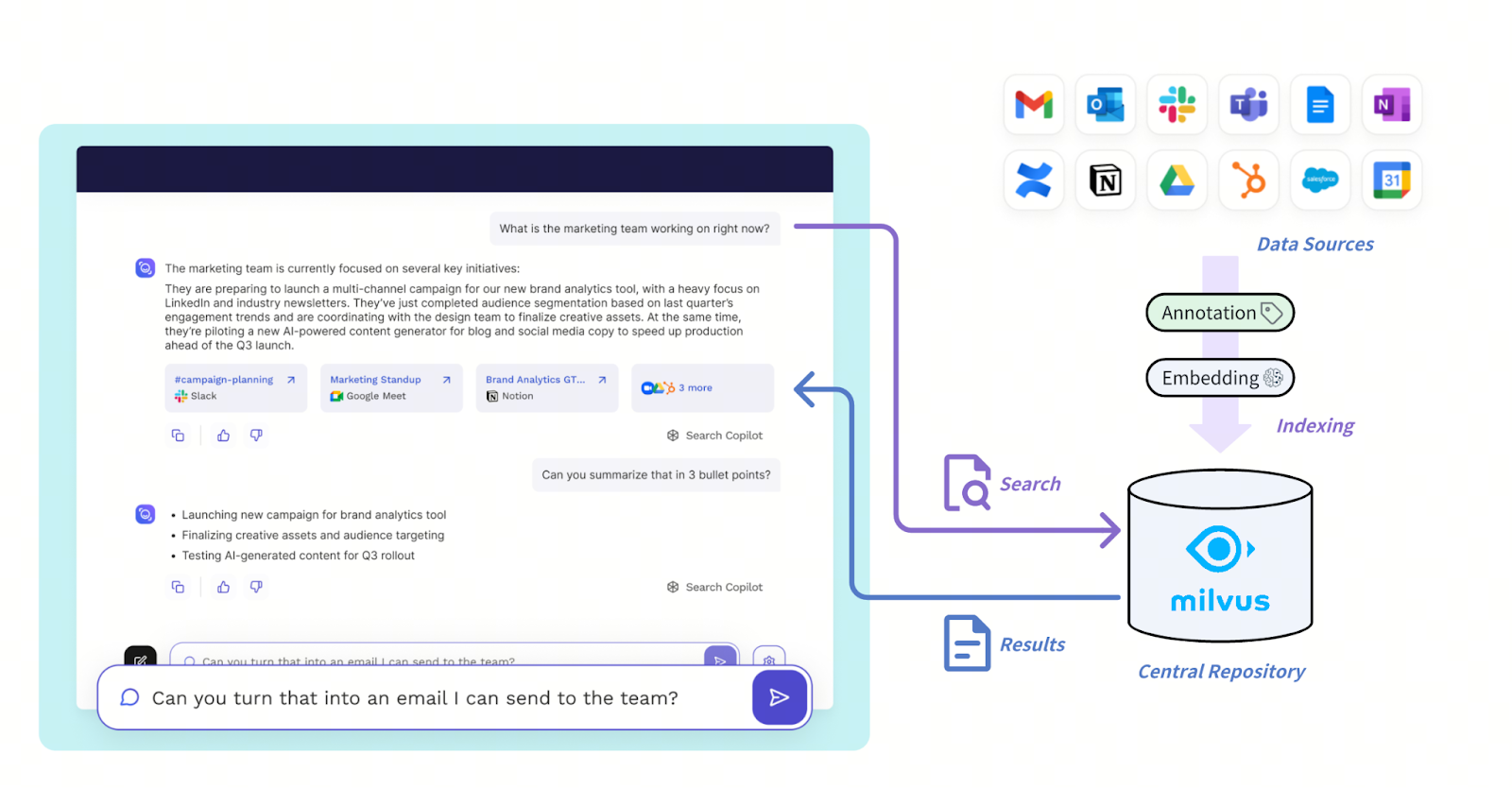 L’architettura della soluzione con Milvus
L’architettura della soluzione con Milvus
Figura: Come Mivus supporta il sistema Read AI
Read AI utilizza una ricerca vettoriale filtrata che combina la similarità vettoriale con il filtraggio basato su metadati strutturati, ad esempio limitando le query a riunioni one-on-one, dipendenti specifici o finestre temporali, consentendo così un recupero più sfumato come “chiamate di vendita con il maggior disimpegno” o “feedback positivo nei one-on-one.” Il filtraggio ottimizzato dei metadati di Milvus è cruciale per ottenere una latenza inferiore a 20-50 ms su questa scala.
"Milvus ci offre un livello di storage consapevole della narrazione — non solo embedding di testo, ma una ricerca pienamente consapevole del contesto." — Rob Williams, Co-Founder and CTO at Read AI
Grazie al supporto nativo multi-tenancy di Milvus, Read AI distribuisce un singolo cluster Milvus per servire in modo efficiente milioni di tenant. Le query sono orchestrate tramite framework agentici interni che analizzano l’intento di ricerca e instradano le richieste in Milvus, quindi post-elaborano i risultati per la consegna tramite interfacce di chat, riepiloghi o avvisi. Questa architettura offre a Read AI la scalabilità e la flessibilità per unificare tipi di contenuti eterogenei mantenendo velocità e precisione, elementi critici per il recupero in tempo reale e l’analisi retrospettiva.
Valutazione tecnica e processo decisionale
Prima di adottare Milvus, il team di Read AI ha valutato diverse alternative. FAISS è stato escluso a causa della mancanza di multi-tenancy integrata e delle capacità di filtraggio limitate. Pinecone non offriva la flessibilità necessaria per supportare il pattern di ricerca e la scala di Read AI. È stata presa in considerazione anche una soluzione completamente self-hosted e sviluppata internamente, ma non riusciva a soddisfare i requisiti di scalabilità e maturità del loro caso d’uso. Milvus si è distinto sulla base di diversi fattori chiave:
La capacità di scalare fino a milioni di utenti e miliardi di record
Latenza costante inferiore a 20-50 ms su grandi collezioni vettoriali
Supporto per workflow di ricerca ibrida
Isolamento a livello di tenant
La developer experience è stata un altro fattore decisivo, con documentazione chiara, maintainer reattivi e supporto ingegneristico pratico, soprattutto durante la loro proof-of-concept. La fase di PoC ha dimostrato tempi rapidi di risposta sui carichi di lavoro di test e ha fornito assistenza di debug in tempo reale da parte del team Milvus, dando a Read AI la fiducia necessaria per passare alla produzione.
Risultati e vantaggi della scelta di Milvus
Da quando ha implementato Milvus e in concomitanza con il lancio dello strumento di enterprise search Search Copilot dell’azienda, Read AI ha ottenuto un incremento di velocità di 5× nella ricerca agentica su diverse fonti di dati, mantenendo una latenza di recupero costante di circa 20-50 ms, anche durante la gestione di query con filtri complessi. La piattaforma ha integrato senza problemi milioni di account utente individuali in un grande cluster senza interruzioni, dimostrando la robustezza dell’architettura distribuita di Milvus e della sua capacità di multi-tenancy.
Milvus alimenta un livello di ricerca unificato su tutti i canali di comunicazione—riunioni, chat, email e CRM. Lo scaling elastico semplifica l’operatività per gestire coorti enterprise o picchi di traffico. Funzionalità come l’importazione bulk portano a un’esperienza fluida durante l’onboarding di grandi quantità di dati storici quando nuove aziende si iscrivono al servizio.
Ancora più importante, Milvus alimenta il passaggio da una ricerca reattiva a una proattiva: facendo emergere insight pertinenti, attività da svolgere e rischi prima ancora che gli utenti lo chiedano, grazie alla ricerca vettoriale a bassa latenza su contesti dinamici e multimodali. Questa capacità non solo migliora l’esperienza utente, ma sblocca anche nuove opportunità di business mentre Read AI continua a concentrarsi sull’espansione della piattaforma con continui progressi nelle raccomandazioni predittive e nei passaggi successivi.
"Ciò che volevamo era portare l’intelligenza all’utente prima ancora che la chiedesse. Milvus è ciò che lo ha reso fattibile." —Rob Williams, Co-Founder and CTO at Read AI
Questi successi tecnici si traducono direttamente in valore di business: gli utenti del livello gratuito ricevono insight significativi in pochi minuti, favorendo la retention, mentre i clienti enterprise beneficiano di un recupero della conoscenza più approfondito e di un contesto a lungo termine, aumentando la fiducia degli utenti e supportando opportunità di upsell premium.
Approfondimenti per sviluppatori e ingegneri
Lezioni dall’implementazione:
L’annotazione strutturata può alimentare output LLM downstream più ricchi
La ricerca vettoriale deve mantenere la propria velocità, anche con il filtraggio dei metadati strutturati, per stare al passo con l’esperienza utente della ricerca
L’isolamento multi-tenant e la scalabilità dinamica sono imprescindibili su scala consumer
Il team conduce esperimenti continui, monitorando le prestazioni delle query, la soddisfazione degli utenti e le metriche comportamentali per perfezionare continuamente il modo in cui gli agenti cercano, filtrano e classificano i risultati.
Read AI elabora i dati conversazionali non solo con modelli di embedding, ma anche con un livello di narrazione unico. Questa astrazione semantica va oltre le trascrizioni per cogliere tono, intento ed eventi chiave come l’avanzamento di una trattativa o il calo del coinvolgimento. Di conseguenza, gli utenti possono cercare narrazioni in linguaggio naturale, come "chi era disinteressato durante la demo," anziché limitarsi alla corrispondenza di parole chiave.
Roadmap
Guardando al futuro, Read AI si concentra sul miglioramento del modo in cui bilancia carichi di lavoro in tempo reale e offline, con piani per costruire un’orchestrazione più dinamica tra dati in streaming live e archiviazione a lungo termine. Sta esplorando l’uso del prossimo Vector Lake di Milvus per ridurre i costi di ricerca spostando le query offline con aspettative di latenza meno stringenti verso un livello in stile warehouse supportato da object storage.
Un’altra area chiave di sviluppo è il rilevamento automatico delle lacune di conoscenza — identificare quando informazioni critiche mancano o sono scollegate — e portare proattivamente gli insight all’attenzione degli utenti prima che li richiedano. Tutti questi miglioramenti supportano la visione a lungo termine di Read AI: costruire un “action engine” per l’impresa — una piattaforma basata sull’AI, sempre attiva e consapevole del contesto, che potenzi in modo intelligente i knowledge worker su tutti i canali di comunicazione.
Archiviando il contesto conversazionale e gli insight storici in Milvus, Read AI estende la disponibilità della conoscenza istituzionale, facendo emergere informazioni critiche anche quando il partecipante originale è offline o non lavora più in azienda.
Conclusione
Il percorso di Read AI da strumento di analisi delle riunioni a piattaforma di intelligence su vasta scala per il grande pubblico ha richiesto un’infrastruttura capace di gestire una scala enorme, dati eterogenei e requisiti di query complessi e in tempo reale. Milvus si è dimostrato la scelta giusta — non solo per le sue prestazioni grezze e la sua scalabilità, ma per la sua flessibilità nel supportare embedding annotati, filtraggio dei metadati e isolamento multi-tenant.
Con Milvus come fondamento della sua infrastruttura di ricerca vettoriale, Read AI offre risultati e raccomandazioni veloci, affidabili e profondamente contestuali a milioni di utenti. Man mano che si espande verso la costruzione di un action engine intelligente e sempre attivo per l’impresa, Milvus continua a supportare la sua esigenza di efficienza dei costi, flessibilità architetturale e scalabilità a prova di futuro, dimostrando che un database vettoriale ben progettato è più di un semplice storage; è la spina dorsale della moderna comprensione delle informazioni.
What we wanted was to push intelligence to the user before they even asked. Milvus is what made that viable.
Rob Williams