




VDBBench aggiunge benchmark consapevoli dei costi per i database vettoriali
L'anno scorso abbiamo rilasciato VectorDBBench 1.0 per rendere il benchmarking dei database vettoriali più vicino ai carichi di lavoro di produzione. Invece di testare solo il QPS di picco su dati di benchmark fissi, VectorDBBench (noto anche come VDBBench) consente ai team di valutare i database vettoriali usando pattern di carico di lavoro che riflettono più da vicino i propri sistemi di produzione: ingestione, filtraggio, recall, latenza, concorrenza e dataset personalizzati.
L'ultima release di VDBBench aggiunge una nuova dimensione: il costo.
I team di produzione raramente scelgono un database vettoriale solo in base alle prestazioni. Devono sapere quanto costa raggiungere un QPS target, come si comporta il P99 in quel modello di costo, quando i dati inseriti diventano ricercabili, quando sono completamente indicizzati, in che modo la dimensione del payload influisce sulla ricerca, come si comporta il sistema con molti tenant e cosa succede alla prima query dopo un periodo di inattività. Queste domande ora fanno parte di VDBBench.
Per mostrare come funzionano in pratica questi nuovi benchmark attenti ai costi, abbiamo testato tre prodotti di database vettoriali gestiti comunemente valutati: Zilliz Cloud, Turbopuffer e Pinecone. I risultati sono pubblicati nella nuova VDBBench Cost Leaderboard, con grafici e tabelle che confrontano prontezza degli inserimenti, ricerca con payload, ricerca multitenant, latenza a freddo e compromessi costo-prestazioni.
La leaderboard è solo un modo per leggere i risultati — è un'istantanea di tre prodotti in un determinato momento. Poiché VDBBench è open source, i team possono anche riprodurre questi casi, eseguire benchmark su prodotti che non sono presenti nella leaderboard o adattare i carichi di lavoro ai propri dati simili a quelli di produzione.
L'obiettivo non è incoronare un vincitore universale, ma aiutare i team a scegliere il database vettoriale che meglio si adatta al loro carico di lavoro, ai target di prestazioni e al budget.
- Riferimenti: VectorDBBench GitHub | VDBBench Leaderboards
Novità in VDBBench
Questa release aggiunge quattro casi di benchmark orientati al cloud che misurano comportamenti di produzione che le leaderboard basate sul QPS di picco spesso non colgono.
| Caso | Cosa misura | Perché è importante |
|---|---|---|
| CloudInsertCase | Completamento dell'inserimento, stato ricercabile, stato completamente indicizzato e costo di scrittura | Freschezza e costo di backfill sono importanti per RAG, cataloghi e memoria degli agenti |
| CloudPayloadSearchCase | QPS, latenza P99, recall e forma del payload di risposta | Restituire vettori o metadati può cambiare la superficie di costo della ricerca |
| MultitenantSearchCase | Throughput su molti tenant o namespace | I carichi di lavoro SaaS sollecitano routing e comportamento delle partizioni in modo diverso rispetto alla ricerca single-tenant |
| CloudColdLatencyCase | Prima query dopo inattività vs. percorso di query riscaldato | Il comportamento a cold start è importante per tenant a bassa frequenza e memoria degli agenti |
Oltre a questi casi, la Cost Leaderboard aggiunge una vista costo-Pareto che modella i costi operativi a livelli di QPS target in base ai limiti di servizio misurati di ciascun prodotto — perché le decisioni di acquisto di solito dipendono dal punto in cui prestazioni e costo si intersecano.
La VDBBench Cost Leaderboard usa questi casi per confrontare pubblicamente prodotti gestiti. Poiché i casi sono inclusi in VDBBench open source, i team possono riutilizzarli per la propria valutazione, compresi prodotti e carichi di lavoro non mostrati nella leaderboard.
Chi abbiamo testato: Zilliz Cloud vs. Turbopuffer vs. Pinecone
Per questa prima esecuzione attenta ai costi, abbiamo testato tre prodotti di database vettoriali gestiti comunemente valutati. Tutti i prodotti sono stati sottoposti a benchmark il 10 maggio 2026, in AWS US West (us-west-2). I loro modelli operativi differiscono, quindi i risultati dovrebbero essere interpretati in termini di adattamento al carico di lavoro anziché come una singola classifica.
| Prodotto | Ruolo in questo benchmark |
|---|---|
| Zilliz Cloud | Database vettoriale cloud gestito e vector lakebase dai creatori di Milvus, testato nelle sue configurazioni Tiered e Capacity |
| Turbopuffer | Database vettoriale serverless testato nelle modalità unpinned e pinned |
| Pinecone Serverless | Database vettoriale serverless maturo a bassa operatività usato come punto di riferimento comune per la produzione |
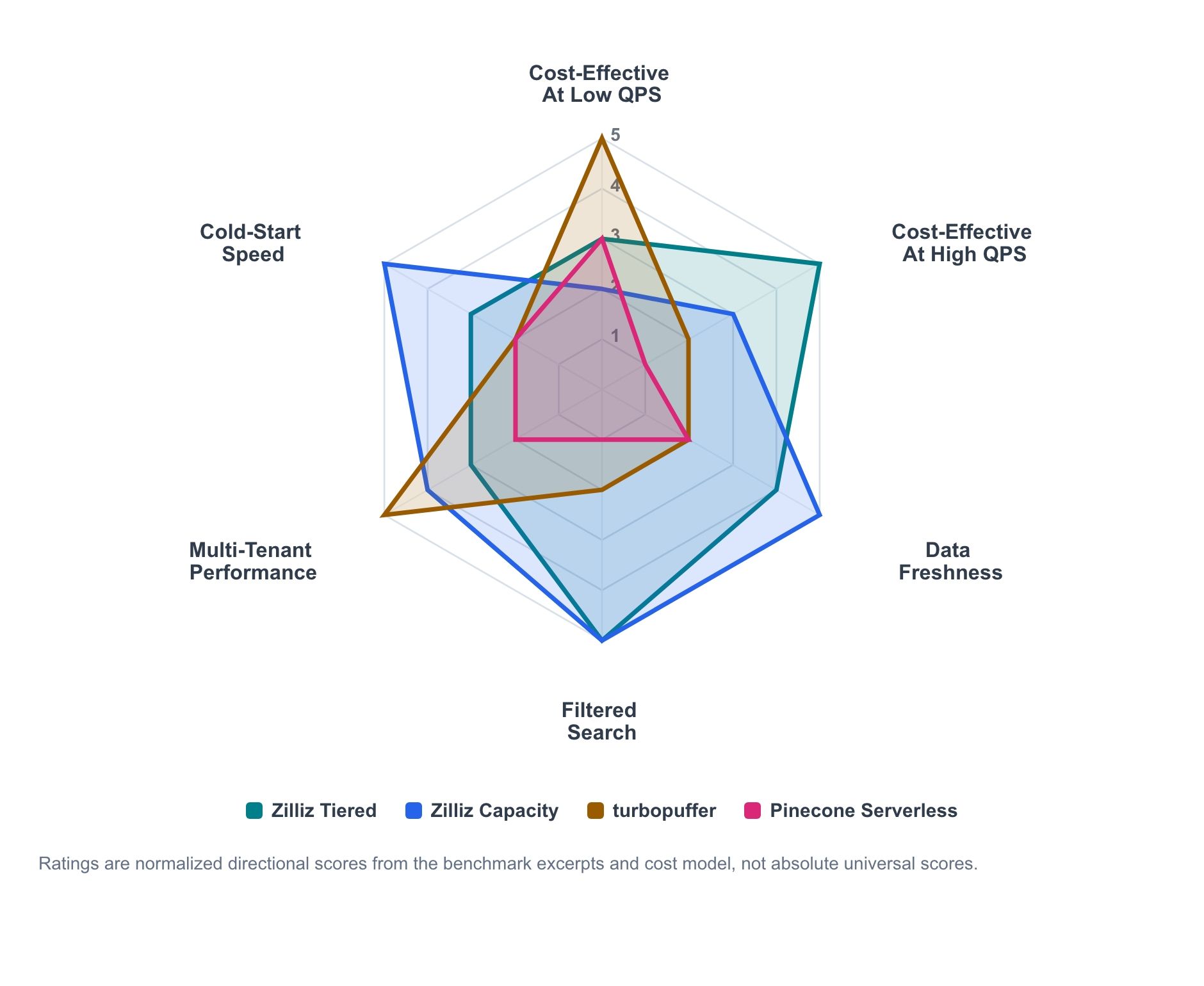
Figura 1. Sintesi direzionale dell’idoneità al carico di lavoro basata su estratti del benchmark e modellazione dei costi. I punteggi sono normalizzati per il confronto tra dimensioni del carico di lavoro e non devono essere letti come classifiche assolute universali.
Il grafico radar sintetizza il segnale direzionale dagli estratti del benchmark e dal modello dei costi. Non è una pagella assoluta; è una mappa di dove ciascun prodotto tende a essere più forte.
- Zilliz Cloud Tiered è la linea economica per serving attivo che scala verso l’alto all’aumentare dell’utilizzo.
- Zilliz Cloud Capacity è il profilo a maggior controllo per serving prevedibile, freschezza e comportamento a freddo.
- Turbopuffer è più forte laddove l’economia serverless a consumo e il throughput orientato ai namespace corrispondono al carico di lavoro.
- Pinecone rimane una baseline serverless utile a bassa operatività, anche quando non rappresenta la frontiera costo-prestazioni in un test specifico.
Il pattern principale è chiaro. L’economia serverless può essere interessante con QPS sostenuti bassi. La capacità provisioned diventa più competitiva all’aumentare dell’utilizzo. Freschezza, ricerca filtrata, dimensione del payload, numero di tenant e comportamento a freddo possono tutti influenzare la decisione.
Dataset e carichi di lavoro
I casi cost-aware utilizzano due forme di carico di lavoro.
- Single-tenant LAION 100M: 100 milioni di vettori densi a 768 dimensioni. Rappresenta una grande raccolta di produzione in cui dimensione del payload, filtri, recall e QPS sostenuti contano.
- Multitenant Cohere 10M: 10 milioni di vettori densi a 768 dimensioni, suddivisi casualmente tra 1.000 tenant — circa 10K vettori per tenant. Rappresenta carichi di lavoro in stile SaaS in cui ogni tenant ha un dataset più piccolo, ma il sistema deve instradare e servire efficientemente molti namespace o partizioni tenant.
Gli estratti seguenti mostrano la forma dei risultati. La Cost Leaderboard e il repository VectorDBBench rimangono la fonte per le matrici complete, le definizioni dei client e i dettagli di riproduzione.
CloudInsertCase: Inserito non significa sempre pronto
La performance di inserimento non è un solo numero. Un database vettoriale gestito può accettare dati dal client prima che tali dati siano sicuri da cercare tramite il percorso di indicizzazione previsto. Per i carichi di lavoro di produzione, i team devono sapere quando l’operazione di inserimento è completata, quando i dati diventano ricercabili e quando l’indicizzazione in background è completamente al passo.
CloudInsertCase misura il ciclo di vita write-to-serve. Questo conta per aggiornamenti di corpora RAG, aggiornamenti di cataloghi prodotti, scritture di memoria degli agenti e backfill di dati. In questi sistemi, "insert accepted" non è sufficiente. La domanda operativa è quando i dati appena scritti possono essere cercati in modo affidabile con prestazioni di produzione.
| Prodotto / modalità | Dimensione batch | Tempo di inserimento | Attesa per ricercabilità | Attesa per indicizzazione completa | Costo di scrittura |
|---|---|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 10.000 | 3,2 h | 0 ms | 1,9 min | $9,50 |
| Zilliz Cloud Tiered 4CU | 10.000 | 4,1 h | 0 ms | 10,9 min | $6,34 |
| Turbopuffer (backpressure off) | 10.000 | 1,8 h | 6,4 h | 2,0 min | $302 |
| Pinecone Serverless | 10.000 | 72,4 h | 0 ms | 127 ms | $1.180 |
Tabella 1. Estratto dell’inserimento batch-10k LAION 100M. Costi e tempi provengono dall’esecuzione corrente della leaderboard. Per le configurazioni Zilliz provisioned, il costo di scrittura è il costo in CU-hour consumato durante la finestra di caricamento e indicizzazione; per Turbopuffer e Pinecone, è l’addebito di scrittura a consumo. Leggere i tempi insieme alle definizioni client per gli stati inserito, ricercabile e completamente indicizzato (definite per ciascun client nel sorgente VDBBench).
Le dimensioni dei batch cambiano i numeri per prodotti diversi.
- Turbopuffer mostra un forte intake grezzo in batch di grandi dimensioni, soprattutto con backpressure disabilitata — la sua modalità di intake più aggressiva. Nel percorso batch-10k, completa rapidamente l’inserimento, ma l’attesa per la ricercabilità domina l’intera finestra di readiness.
- Zilliz Cloud è più stabile tra le diverse dimensioni dei batch. Nelle configurazioni Capacity e Tiered testate, i dati diventano ricercabili immediatamente dopo il completamento dell’inserimento, e l’attesa residua per l’indicizzazione completa si misura in minuti.
- Pinecone Serverless è il baseline di bulk-intake più lento in questo test. Una volta accettati i dati, l’attesa aggiuntiva per la ricercabilità e l’indicizzazione completa è di fatto pari a zero in queste esecuzioni, ma la fase di inserimento stessa richiede molto più tempo.
La lettura del prodotto dipende dal workload.
- Zilliz si adatta a workflow in cui i dati freschi devono diventare rapidamente ricercabili e indicizzati a un costo prevedibile.
- Turbopuffer si adatta a grandi backfill accettati quando il workload può tollerare una finestra di readiness più lunga.
- Pinecone si adatta a pattern di ingestion serverless a volumi inferiori, dove la semplicità operativa conta più della velocità o del costo del bulk-load.
Il bulk loading è anche un evento di costo. In questo caso di inserimento LAION 100M, le configurazioni Zilliz mantengono il costo lato scrittura nell’ordine di singole cifre in dollari per il percorso batch-10k testato. Turbopuffer è modellato intorno a $302. Pinecone Serverless è modellato intorno a $1,180. Questo non rende un modello di pricing universalmente migliore. Significa che l’economia dell’inserimento dipende dalla frequenza con cui il workload esegue quel percorso.
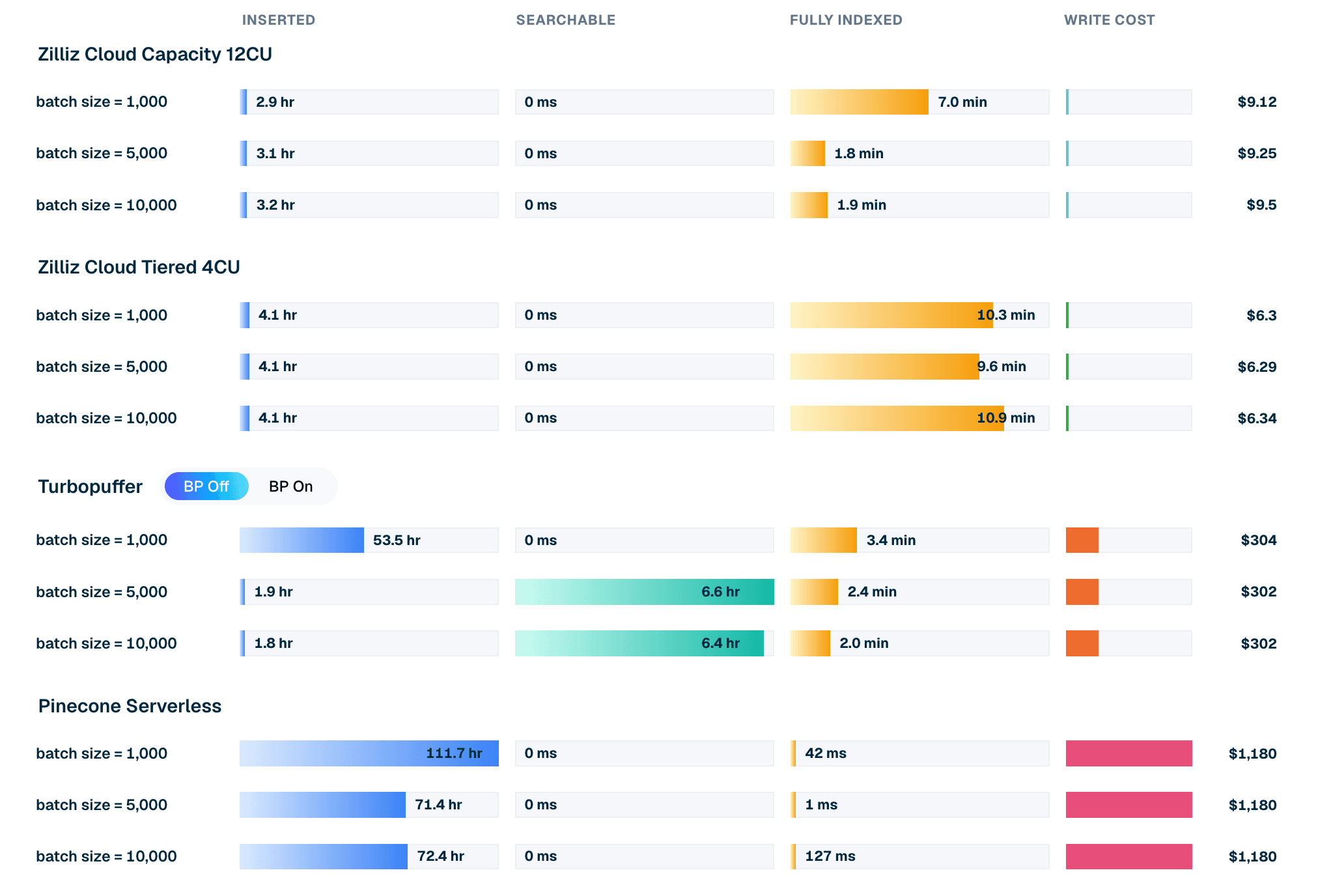
Figura 2. Ciclo di vita dell’inserimento per LAION 100M con batch 10k: tempo di inserimento, attesa per la ricercabilità, attesa per l’indicizzazione completa e costo di scrittura modellato per prodotto.
CloudPayloadSearchCase: il payload cambia la superficie di ricerca
Una volta che i dati sono ricercabili, la domanda successiva non è solo quante query al secondo il database può gestire. La forma della risposta conta. Restituire solo ID è molto diverso dal restituire metadati o vettori grezzi. Un vettore a 768 dimensioni può aggiungere migliaia di byte a ciascun risultato. Con topK=100, la dimensione del payload può diventare un fattore importante nel costo e nella latenza delle query.
CloudPayloadSearchCase testa LAION 100M single-tenant con diversi payload di risposta e forme di filtro. La lettura combina QPS concorrenti massimi, latenza P99 a quella concorrenza, tipo di payload e recall, dove disponibile.
Una nota sulla lettura delle tabelle: P99 qui è misurata alla concorrenza massima — il punto di saturazione che produce il picco di QPS di ciascun prodotto — non a un punto operativo confortevole a livello di servizio. Mostra come si comporta una configurazione al suo limite misurato.
| Prodotto | Latenza P99 @ concorrenza massima | QPS max | recall@10 |
|---|---|---|---|
| Zilliz Cloud Capacity 32CU | 158 ms | 786.1 | 0.9728 |
| turbopuffer | 2.34 s | 395.7 | 0.9321 |
| Zilliz Cloud Capacity 12CU | 299 ms | 376.0 | 0.9723 |
| Turbopuffer pinned | 3.30 s | 68.2 | 0.9321 |
| Zilliz Cloud Tiered 4CU | 5.57 s | 49.2 | 0.9510 |
| Pinecone Serverless | 4.85 s | 4.6 | 0.9609 |
Tabella 2. LAION 100M single-tenant, senza filtri, solo ID, topK 100. Nota su Pinecone: il suo throughput in questo caso single-tenant è limitato dal throttling lato server delle read-unit, quindi l’esecuzione arriva al massimo a concorrenza 4–5, rispetto a 80 per gli altri prodotti. Leggere le sue righe come un baseline serverless regolato piuttosto che come un risultato di saturazione.
La configurazione conta. A 12CU, Zilliz Capacity e Turbopuffer sono vicini sul QPS grezzo in questo caso ampio solo ID, mentre Zilliz è avanti su recall e latenza P99. A 32CU, Zilliz Capacity supera il risultato Turbopuffer testato per questo workload single-tenant.
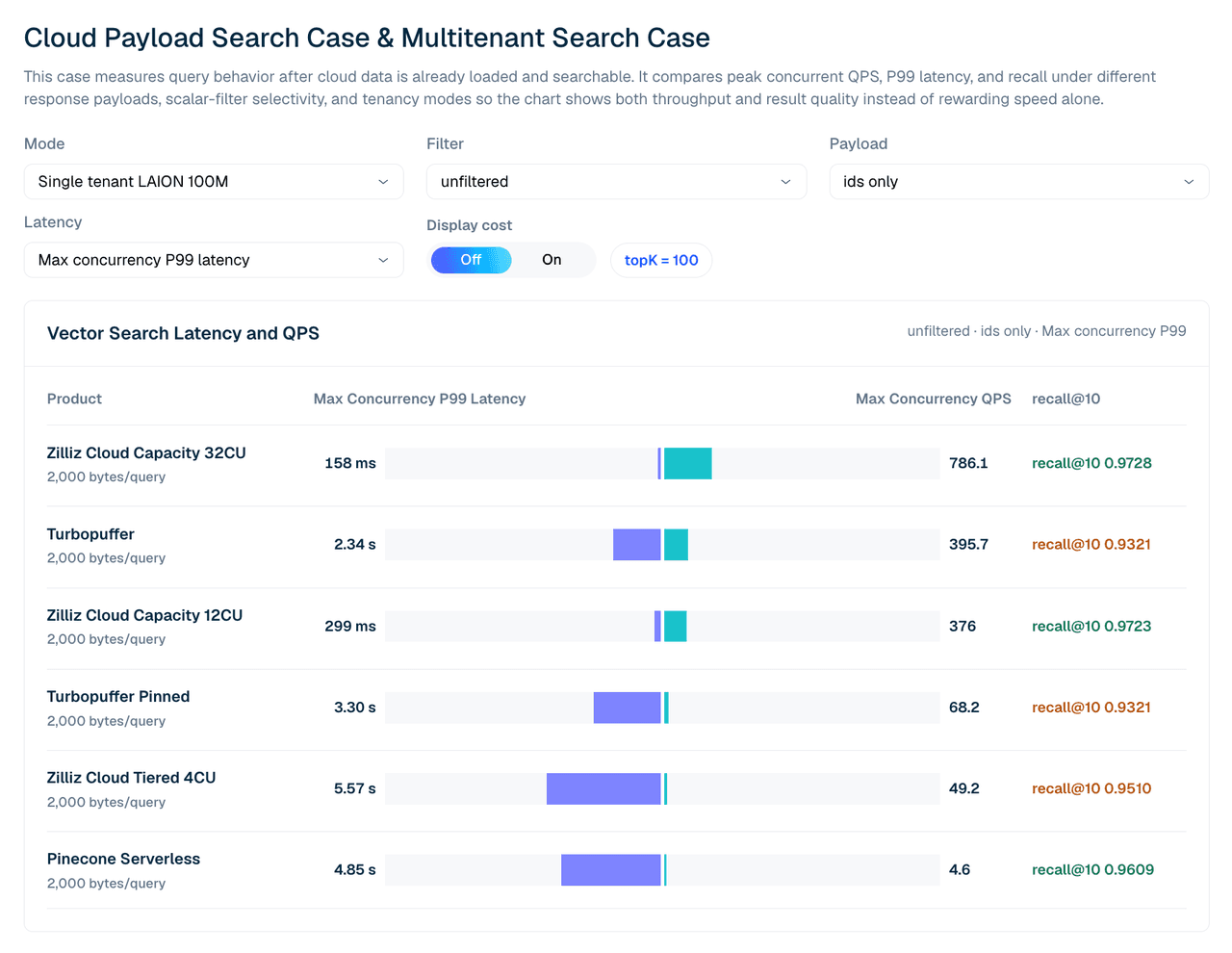
Figura 3. Ricerca LAION 100M single-tenant con risposte solo ID. Questa vista confronta QPS concorrenti massimi, latenza P99 e recall@10 tra le configurazioni gestite testate.
La domanda non è solo quale prodotto sia il più veloce in una configurazione. È come cambiano le prestazioni quando un team acquista più capacità, modifica la forma del payload o ha bisogno di un obiettivo di recall. Quando la query restituisce payload vettoriali grezzi, il throughput può cambiare in modo significativo.
| Prodotto | QPS solo ID | QPS payload vettoriale | Recall |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 49.2 | 44.0 | 0.9510 |
| Zilliz Cloud Capacity 12CU | 376.0 | 229.4 | 0.9723 |
| Zilliz Cloud Capacity 32CU | 786.1 | 531.4 | 0.9728 |
| turbopuffer | 395.7 | 382.2 | 0.9321 |
| Pinecone Serverless | 4.6 | 4.5 | 0.9609 |
Tabella 3. Estratto del payload per retrieval ampio non filtrato. I team dovrebbero eseguire benchmark sulla forma del payload che la loro applicazione restituisce effettivamente, non solo sulla ricerca solo ID.
Ricerca filtrata: dove la selettività conta
Molti workload di ricerca vettoriale in produzione sono soggetti a permessi o filtrati. Un copilot di supporto può cercare solo i documenti che l’utente è autorizzato a vedere. Un sistema di raccomandazione può filtrare per regione, categoria, venditore o disponibilità. Un’app di ricerca aziendale può applicare vincoli di tenant, controllo degli accessi, freschezza e tipo di documento prima di classificare i risultati.
Questi filtri non sono cosmetici. Cambiano il percorso di esecuzione. Nel punto di stress con filtro intero al 99.9% più payload vettoriale, il comportamento del prodotto cambia drasticamente.
| Prodotto | QPS max | Recall | Latenza P99 |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 955.7 | 0.9423 | 0.16 s |
| Zilliz Cloud Capacity 12CU | 933.0 | 0.9781 | 0.12 s |
| turbopuffer | 45.1 | 0.9436 | 7.03 s |
| Pinecone Serverless | 4.8 | —* | 3.30 s |
Tabella 4. Punto di stress con filtro selettivo single-tenant: filtro intero al 99.9% con payload vettoriale. Il recall per l’esecuzione Pinecone Serverless in questo punto di stress non era ancora disponibile al momento della pubblicazione; i suoi QPS e la sua latenza provengono dall’esecuzione misurata.
Questo è uno degli esempi più chiari del perché una valutazione attenta ai costi richieda più forme di workload. Un prodotto che funziona bene nel retrieval ampio non filtrato potrebbe non essere la scelta migliore per la ricerca filtrata selettiva. Per la ricerca soggetta a permessi, il RAG con forte controllo degli accessi o workload con elevata selettività dei filtri, le righe filtrate possono contare più di quelle non filtrate.
MultitenantSearchCase: molti piccoli tenant si comportano in modo diverso
I benchmark single-tenant non catturano ogni workload cloud.
Molte applicazioni AI hanno una forma SaaS. Un prodotto può servire migliaia di tenant, ciascuno con un dataset più piccolo. La sfida operativa non è solo la ricerca vettoriale all’interno di una singola grande collection. È il routing, l’isolamento, la gestione dei namespace e il mantenimento del throughput su molte piccole partizioni.
Il caso multitenant usa il dataset Cohere 10M suddiviso tra 1,000 tenant. La forma della query usa topK 50 e confronta righe solo ID, payload vettoriale e filtrate.
Due note di configurazione influenzano il modo in cui leggere questa tabella.
Primo, le configurazioni Zilliz qui sono intenzionalmente piccole — Tiered 1CU e Capacity 2CU, appena sufficienti a contenere il dataset Cohere 10M. Il caso single-tenant sopra mostra già che i QPS di Zilliz scalano con il numero di CU; la domanda che questo caso pone è l’efficacia in termini di costo con una configurazione dimensionata sui dati, non il throughput di picco.
Secondo, la colonna Pinecone è un’esecuzione separata a bassa concorrenza (concorrenza 4), non normalizzata rispetto alle righe a concorrenza più elevata, quindi va trattata come contesto piuttosto che come confronto diretto.
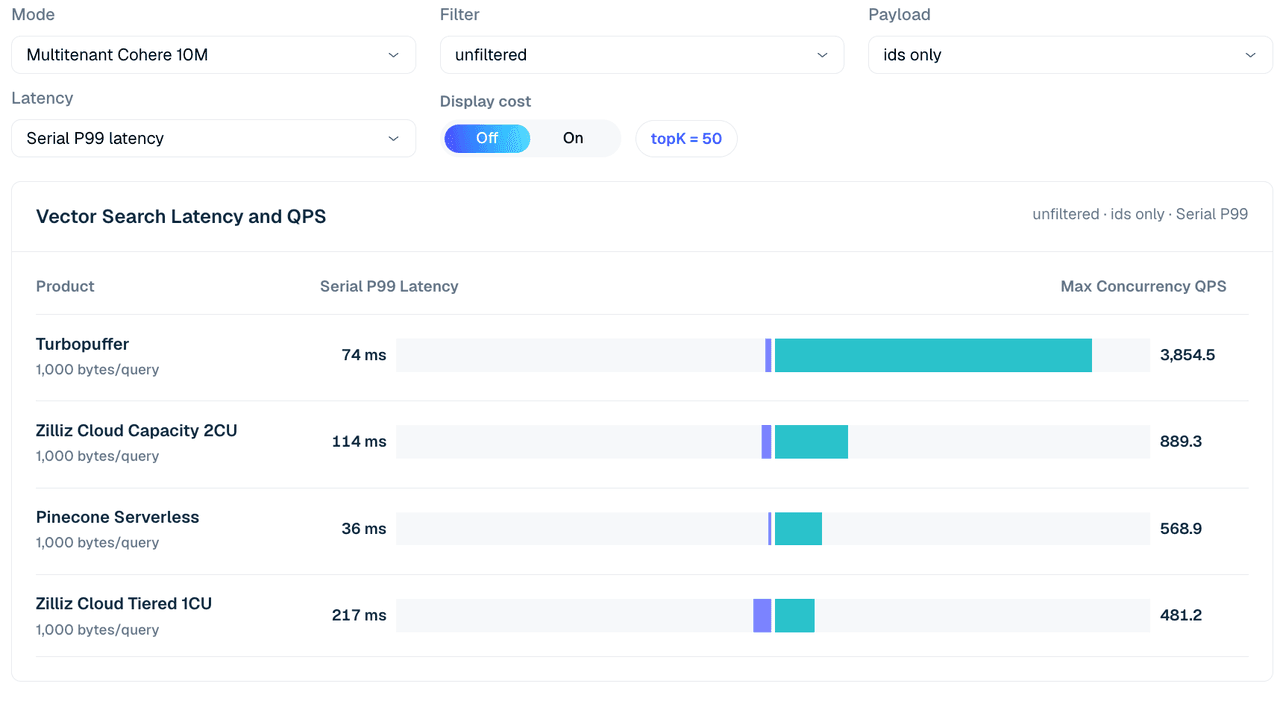
Figura 4. Ricerca multitenant Cohere 10M su 1,000 tenant, solo ID non filtrata, topK 50. La vista confronta la latenza P99 seriale e i QPS concorrenti massimi tra le configurazioni testate; la tabella sotto aggiunge variazioni di payload e filtro.
| Caso | Zilliz Tiered 1CU | Zilliz Capacity 2CU | turbopuffer | Pinecone (c4 run) |
|---|---|---|---|---|
| Non filtrato, solo ID | 481 | 889 | 3,855 | 569 |
| Non filtrato, vettore | 34 | 371 | 1,775 | 542 |
| Filtro intero 99,9%, vettore | 625 | 1,307 | 3,835 | 526 |
| Etichetta scalare 1%, vettore | 152 | 588 | 1,767 | 600 |
| Etichetta scalare 50%, vettore | 29 | 317 | 1,760 | 562 |
Tabella 5. Estratto della ricerca multitenant su 1.000 tenant, topK 50.
In questa modalità, Turbopuffer è forte su tutta la linea. Raggiunge 3.855 QPS su una ricerca non filtrata solo con ID e 3.835 QPS sulla riga con filtro intero selettivo/vettore. Zilliz Cloud Capacity 2CU rimane il profilo Zilliz più forte in questo estratto, raggiungendo 889 QPS sul caso non filtrato solo con ID e 1.307 QPS sulla riga filtro intero 99,9%/vettore.
La lettura del prodotto è di nuovo modellata dal carico di lavoro. Turbopuffer è molto adatto a molti tenant leggeri e a throughput orientato ai namespace. Zilliz è più forte quando i carichi di lavoro sono filtrati, con permessi, sensibili al recall o più pesanti per tenant, soprattutto quando i team possono scegliere una configurazione Zilliz Capacity che corrisponde all’obiettivo di servizio.
CloudColdLatencyCase: la prima query dopo l’inattività
I cicli di benchmark a caldo possono nascondere il comportamento a freddo. Per molte applicazioni AI in produzione, in particolare memoria degli agenti, RAG long-tail e carichi di lavoro tenant a bassa frequenza, la prima query dopo l’inattività conta. Un sistema può sembrare veloce dopo il riscaldamento, ma aggiunge secondi di latenza quando si accede di nuovo a una collection, un namespace o un percorso di cache a freddo.
CloudColdLatencyCase isola questo comportamento. Misura la prima query su una collection rimasta inattiva per almeno 24 ore — abbastanza a lungo perché cache e percorsi di servizio diventino freddi quanto realisticamente possibile — e la confronta con la prima query sul percorso riscaldato della stessa esecuzione.
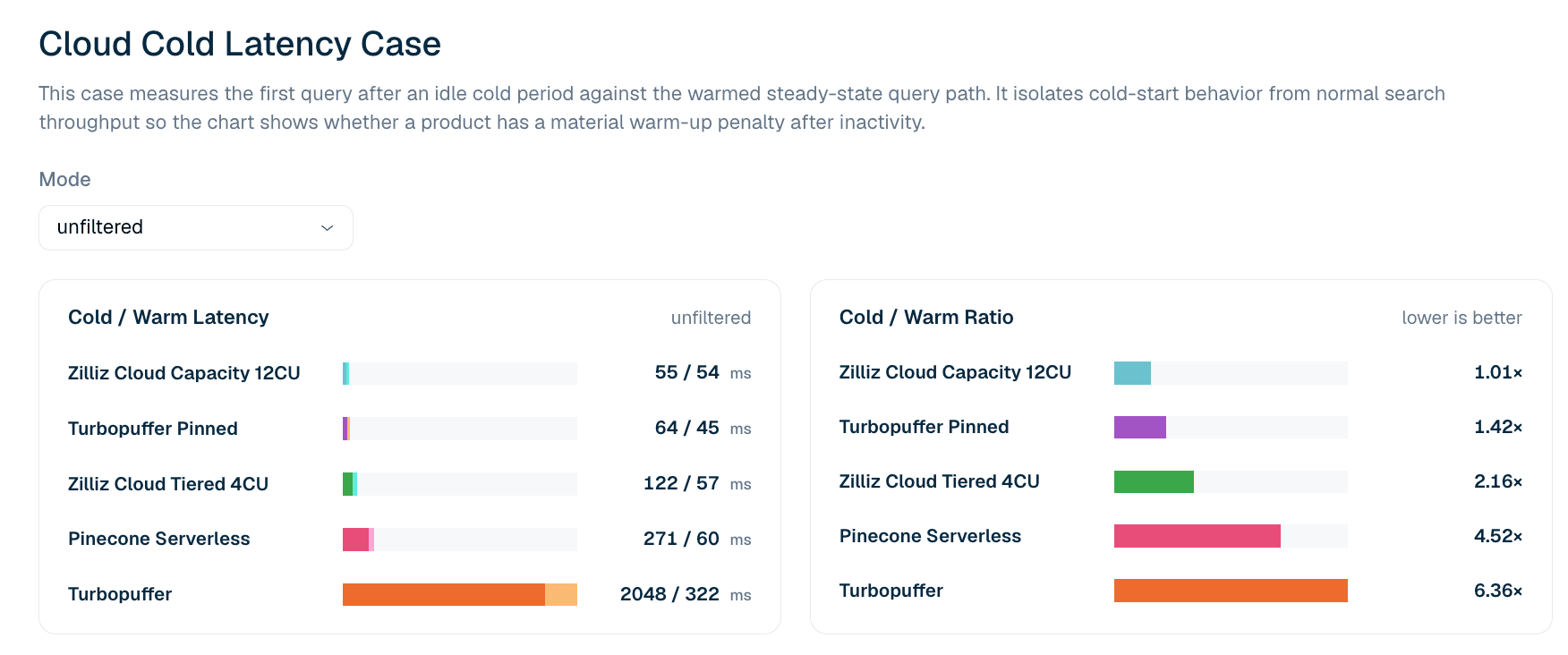
Figura 5. Latenza della prima query dopo l’inattività rispetto al percorso di query riscaldato per la ricerca LAION 100M non filtrata. Il rapporto freddo/caldo evidenzia se un prodotto presenta una penalità materiale sulla prima query dopo l’inattività.
| Prodotto | Prima query dopo l’inattività | Prima query a caldo | Rapporto freddo/caldo |
|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 55 ms | 54 ms | 1.01x |
| Turbopuffer pinned | 64 ms | 45 ms | 1.42x |
| Zilliz Cloud Tiered 4CU | 122 ms | 57 ms | 2.16x |
| Pinecone Serverless | 271 ms | 60 ms | 4.52x |
| turbopuffer | 2,048 ms | 322 ms | 6.36x |
Tabella 6. Estratto della latenza della prima query a freddo e a caldo per LAION 100M non filtrata. Il caso riporta la latenza della prima query anziché i percentili di coda: i rapporti freddo/caldo a P99 tendono a catturare rumore di rete nelle query successive che non si riproduce in modo affidabile, quindi la classifica utilizza la definizione più rigorosa di prima query.
Nel caso attuale di latenza a freddo non filtrata, Zilliz Cloud Capacity 12CU mostra il profilo freddo-caldo più stabile: 55 ms a freddo e 54 ms a caldo, ovvero un rapporto di 1.01x. Turbopuffer pinned ha anch’esso un profilo forte, con 64 ms a freddo e 45 ms a caldo. Turbopuffer non pinned mostra una penalità a freddo maggiore: 2.048 ms a freddo e 322 ms a caldo, ovvero un rapporto di 6.36x.
La latenza a freddo deve sempre essere letta insieme al costo. Le repliche pinned e la capacità provisioned possono ridurre le penalità al primo accesso, ma cambiano il modello economico. Un prodotto può mostrare un comportamento a freddo eccellente perché mantiene più calore. Questo può essere il compromesso giusto per applicazioni interattive, ma non dovrebbe essere separato dal costo di mantenimento di quel percorso.
Linee di Pareto dei costi: dove i modelli di prezzo si incrociano
Un listino prezzi non basta. Un prezzo unitario basso non aiuta se il prodotto non può raggiungere il QPS target. Una configurazione ad alto throughput non è attraente se costa più di un altro prodotto che soddisfa gli stessi requisiti di latenza, recall e payload.
La vista Pareto dei costi combina i limiti misurati dei benchmark con i modelli di prezzo. Per lo scenario LAION 100M solo query, ogni linea di prodotto si ferma al QPS massimo osservato nel benchmark. Il grafico stima quindi il costo operativo ai livelli di QPS target e contrassegna le scelte Pareto-ottimali entro tali vincoli misurati.
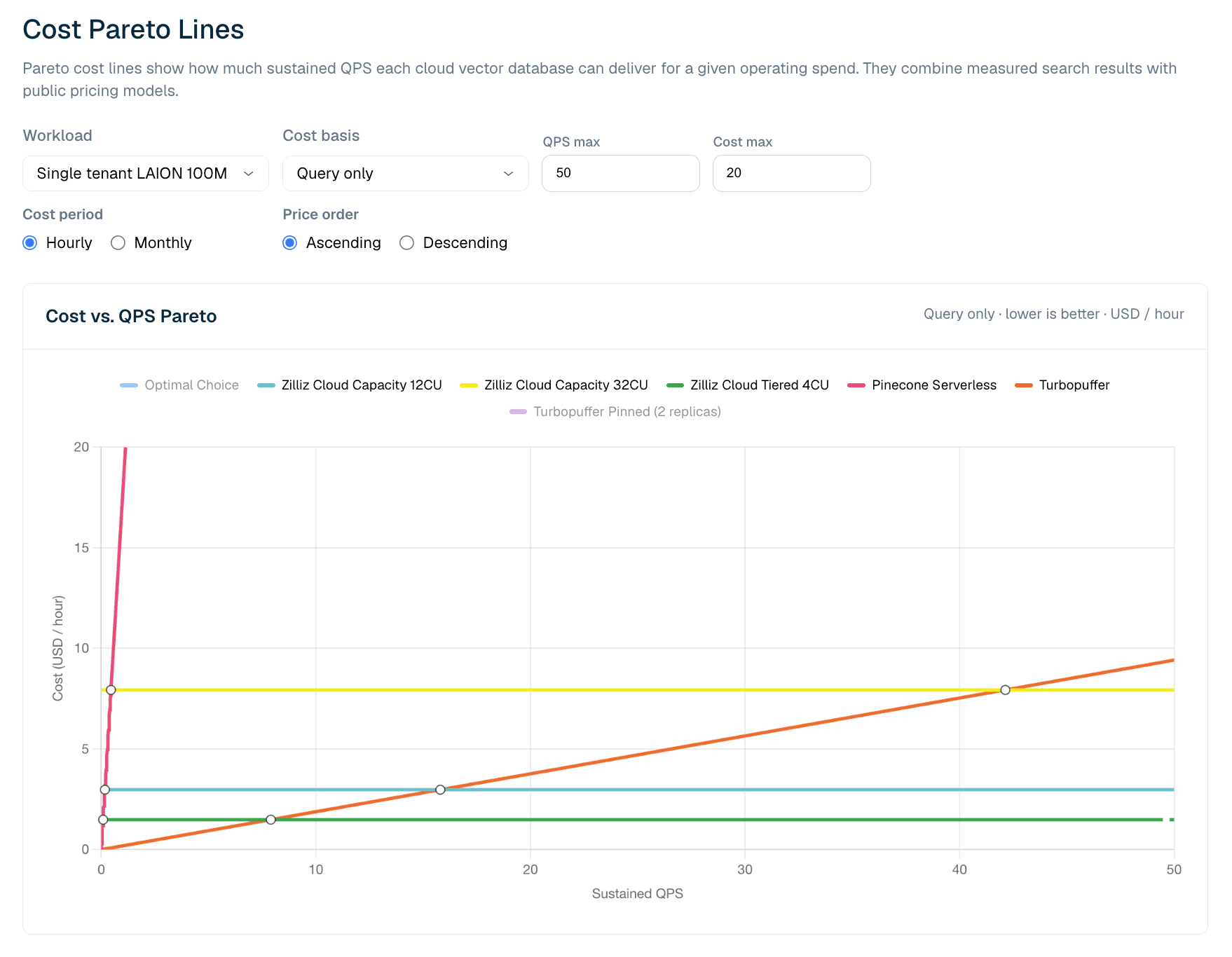
Figura 6. Costo vs. QPS sostenuto per workload LAION 100M solo query. La vista Pareto mostra dove il pricing serverless è più efficiente a basso QPS e dove le configurazioni Zilliz provisioned diventano più convenienti con l'aumentare dell'utilizzo.
Nell'attuale modello LAION 100M solo query, Turbopuffer ha il vantaggio a QPS sostenuto molto basso. Il punto di crossover misurato si colloca intorno a 8 QPS: al di sotto, il pricing delle query a consumo di turbopuffer è la linea più economica; al di sopra, Zilliz Cloud Tiered 4CU diventa più economico, perché il suo costo di serving in CU-ora è per lo più fisso una volta effettuato il provisioning. Con l'aumentare del QPS, l'utilizzo migliora e la capacità provisioned diventa più conveniente.
Questo non significa che il serverless sia peggiore. Significa che le economie di serverless e provisioned si incrociano. Per workload bassi, irregolari o imprevedibili, il serverless a consumo può essere la soluzione più adatta. Per il traffico di produzione sostenuto, un modello fisso a CU-ora può diventare più economico una volta che l'utilizzo supera il punto di crossover. Per i team che necessitano di envelope di serving più robusti, comportamento a freddo o controllo operativo, Zilliz Capacity può essere il profilo giusto anche quando Tiered è la linea a costo inferiore.
Zilliz Cloud vs. Turbopuffer vs. Pinecone: soluzione più adatta per workload
| Forma del workload | Segnale più forte | Perché |
|---|---|---|
| QPS sostenuto molto basso | turbopuffer | Le economie serverless a consumo sono interessanti prima del crossover a basso QPS |
| QPS sostenuto sopra il crossover (~8 QPS in questo modello) | Zilliz Cloud Tiered | Le economie fisse a CU-ora migliorano con l'aumentare dell'utilizzo |
| Dati freschi o aggiornamenti frequenti | Zilliz Cloud Capacity / Tiered | Insert-to-search e prontezza completamente indicizzata sono forti nel caso di inserimento LAION 100M |
| Sensibilità al costo di un grande caricamento completo | Zilliz Cloud Capacity / Tiered | Il costo lato scrittura è molto più basso nel percorso di bulk-load LAION 100M testato |
| Ricerca ampia non filtrata sul payload | Turbopuffer e Zilliz Capacity 32CU | Turbopuffer è forte nel retrieval ampio; Zilliz scala con maggiore capacità |
| Filtri selettivi o ricerca con permessi | Zilliz Cloud Capacity / Tiered | Zilliz mostra QPS molto più elevato e latenza P99 inferiore nel punto di stress con filtro al 99,9% |
| Molti tenant leggeri | turbopuffer | QPS grezzo più alto nell'estratto con 1.000 tenant |
| App interattive sensibili al cold start | Zilliz Cloud Capacity; Turbopuffer pinned | Entrambi riducono le penalità della prima query, con modelli di costo diversi |
| Baseline serverless a basse operazioni | Pinecone Serverless | Punto di riferimento serverless maturo, anche quando non è all'avanguardia in questo workload |
Come utilizzare questi risultati di benchmarking
VDBBench e la sua Cost Leaderboard sono progettati per far sì che la valutazione dei database vettoriali rifletta più da vicino il modo in cui i team acquistano e gestiscono effettivamente prodotti cloud gestiti. Il QPS di picco conta ancora, ma da solo non è più sufficiente. La domanda più utile è se un prodotto possa soddisfare simultaneamente i requisiti del workload in termini di latenza, recall, freschezza, payload, tenancy e costo.
Un flusso di valutazione pratico si presenta così:
- Usa la Performance Leaderboard per comprendere la capacità di serving grezza in condizioni di benchmark controllate.
- Usa la Cost Leaderboard per comprendere i trade-off costo-prestazioni tra prodotti cloud gestiti e forme di workload.
- Usa VDBBench stesso per riprodurre i casi, testare altri prodotti o eseguire il benchmark su dati e distribuzioni di query simili alla produzione.
I risultati attuali dovrebbero essere letti con diverse avvertenze.
- I prodotti sono stati sottoposti a benchmark il 10 maggio 2026 e il modello di costo utilizza i prezzi AWS us-west-2 in vigore a tale data. I prezzi possono variare in base alla data e alla regione.
- Le scelte di configurazione, come modalità pinned, capacità provisioned, controlli di scaling e throttling serverless, possono influire sui risultati.
- Gli stati di readiness non sono sempre esposti nello stesso modo, quindi le definizioni di inserito, ricercabile e completamente indicizzato devono essere verificate per ciascun client.
- Infine, i workload sono specifici per scelta progettuale. I risultati Cost Pareto devono sempre essere letti insieme a latenza, recall, forma del payload e limiti di serving misurati.
Esegui il benchmark dei tuoi workload
La Cost Leaderboard è un’istantanea pubblica dei risultati attuali, ma il cambiamento più importante è in VDBBench stesso. Ora consente ai team di valutare insieme performance e costo rispetto a vincoli specifici del workload: freshness, dimensione del payload, forma del tenant, comportamento a freddo e modello operativo.
Un prodotto serverless può essere adatto per un QPS sostenuto basso. La capacità provisioned può diventare più conveniente una volta che l’utilizzo aumenta. Un sistema può essere in testa nel retrieval ampio, mentre un altro può offrire prestazioni migliori con filtri selettivi, refresh frequenti o workload sensibili al cold start.
L’obiettivo non è il miglior numero da titolo. È la soluzione più adatta al tuo workload.
- Visualizza i risultati attuali: VDBBench Cost Leaderboard
- Riproduci questi casi oppure esegui il benchmark dei tuoi candidati: VectorDBBench su GitHub
- Domande o risultati da condividere? Apri una issue su GitHub o partecipa alla conversazione su Discord

Continua a leggere

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.