




Vi presentiamo DeepSearcher: Una ricerca profonda locale open source
 deep researcher.gif
deep researcher.gif
Nel post precedente, "I Built a Deep Research with Open Source-and So Can You!", abbiamo spiegato alcuni dei principi alla base degli agenti di ricerca e abbiamo costruito un semplice prototipo che genera rapporti dettagliati su un determinato argomento o domanda. L'articolo e il notebook corrispondente hanno dimostrato i concetti fondamentali di uso dello strumento, decomposizione della domanda, ragionamento e riflessione. L'esempio del nostro post precedente, a differenza della Deep Research di OpenAI, è stato eseguito localmente, utilizzando solo modelli e strumenti open-source come Milvus e LangChain. (Vi invito a leggere l'articolo sopra prima di continuare).
Nelle settimane successive c'è stata un'esplosione di interesse per la comprensione e la riproduzione della ricerca profonda di OpenAI. Si veda, ad esempio, Perplexity Deep Research e Hugging Face's Open DeepResearch. Questi strumenti differiscono per architettura e metodologia, pur condividendo un obiettivo: ricercare iterativamente un argomento o una domanda navigando sul web o su documenti interni e produrre un rapporto dettagliato, informato e ben strutturato. È importante notare che l'agente sottostante automatizza il ragionamento sulle azioni da intraprendere in ogni fase intermedia.
In questo post, ci basiamo sul nostro post precedente e presentiamo il progetto open-source DeepSearcher di Zilliz. Il nostro agente dimostra ulteriori concetti: query routing, flusso di esecuzione condizionale e web crawling come strumento. È presentato come una libreria Python e uno strumento a riga di comando piuttosto che come un taccuino Jupyter ed è più completo rispetto al nostro post precedente. Ad esempio, è in grado di inserire più documenti sorgente e di impostare il modello di embedding e il database vettoriale utilizzato tramite un file di configurazione. Sebbene sia ancora relativamente semplice, DeepSearcher è un ottimo esempio di RAG agenziale e rappresenta un ulteriore passo avanti verso le applicazioni di IA più avanzate.
Inoltre, esploriamo la necessità di servizi di inferenza più veloci ed efficienti. I modelli di ragionamento fanno uso dello "scaling dell'inferenza", cioè di calcoli extra, per migliorare i loro risultati, e questo, combinato con il fatto che una singola relazione può richiedere centinaia o migliaia di chiamate LLM, fa sì che la larghezza di banda dell'inferenza sia il principale collo di bottiglia. Noi usiamo il modello di ragionamento DeepSeek-R1 sull'hardware personalizzato di SambaNova, che è due volte più veloce, in termini di tokens-per-second, del concorrente più vicino (vedi figura sotto).
SambaNova Cloud fornisce anche un servizio di inferenza per altri modelli open-source, tra cui Llama 3.x, Qwen2.5 e QwQ. Il servizio di inferenza viene eseguito sul chip personalizzato di SambaNova chiamato RDU (reconfigurable dataflow unit), appositamente progettato per un'inferenza efficiente sui modelli di IA generativa, riducendo i costi e aumentando la velocità di inferenza. Per saperne di più, visitate il loro sito web
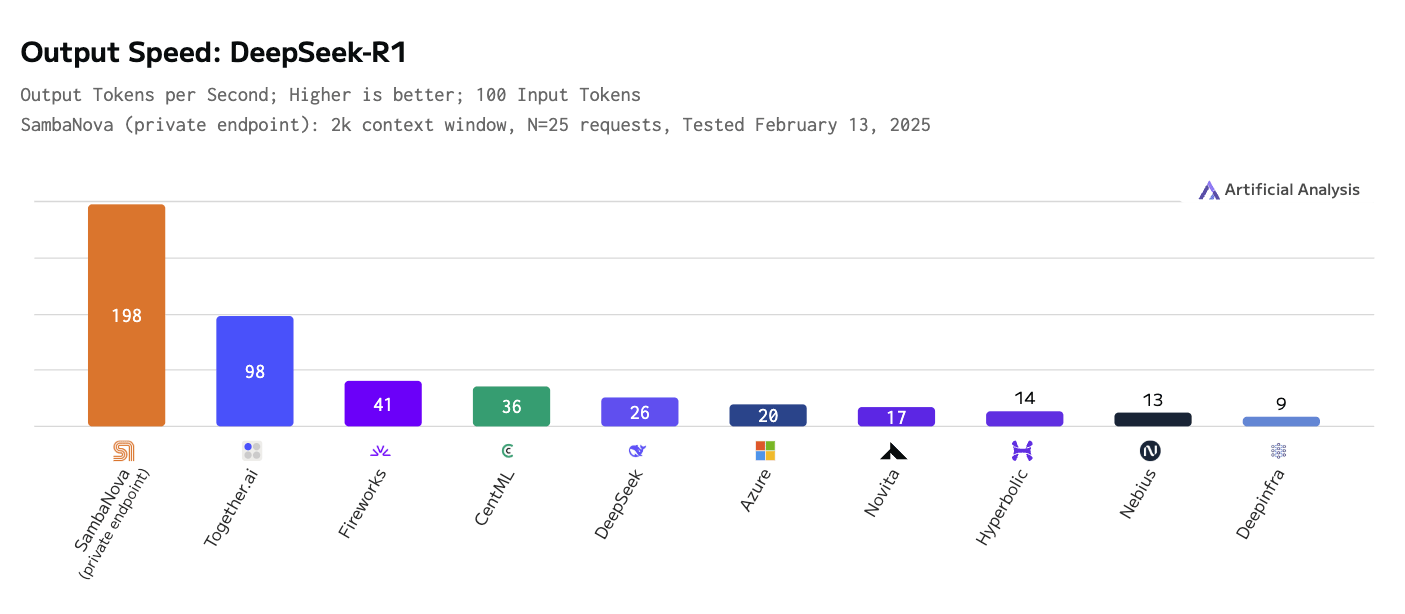 Velocità di uscita - deepseek r1.png
Velocità di uscita - deepseek r1.png
Architettura di DeepSearcher
L'architettura di DeepSearcher segue il nostro precedente post suddividendo il problema in quattro fasi - definire/raffinare la domanda, ricercare, analizzare, sintetizzare - anche se questa volta con qualche sovrapposizione. Esaminiamo ogni fase, evidenziando i miglioramenti di DeepSearcher.
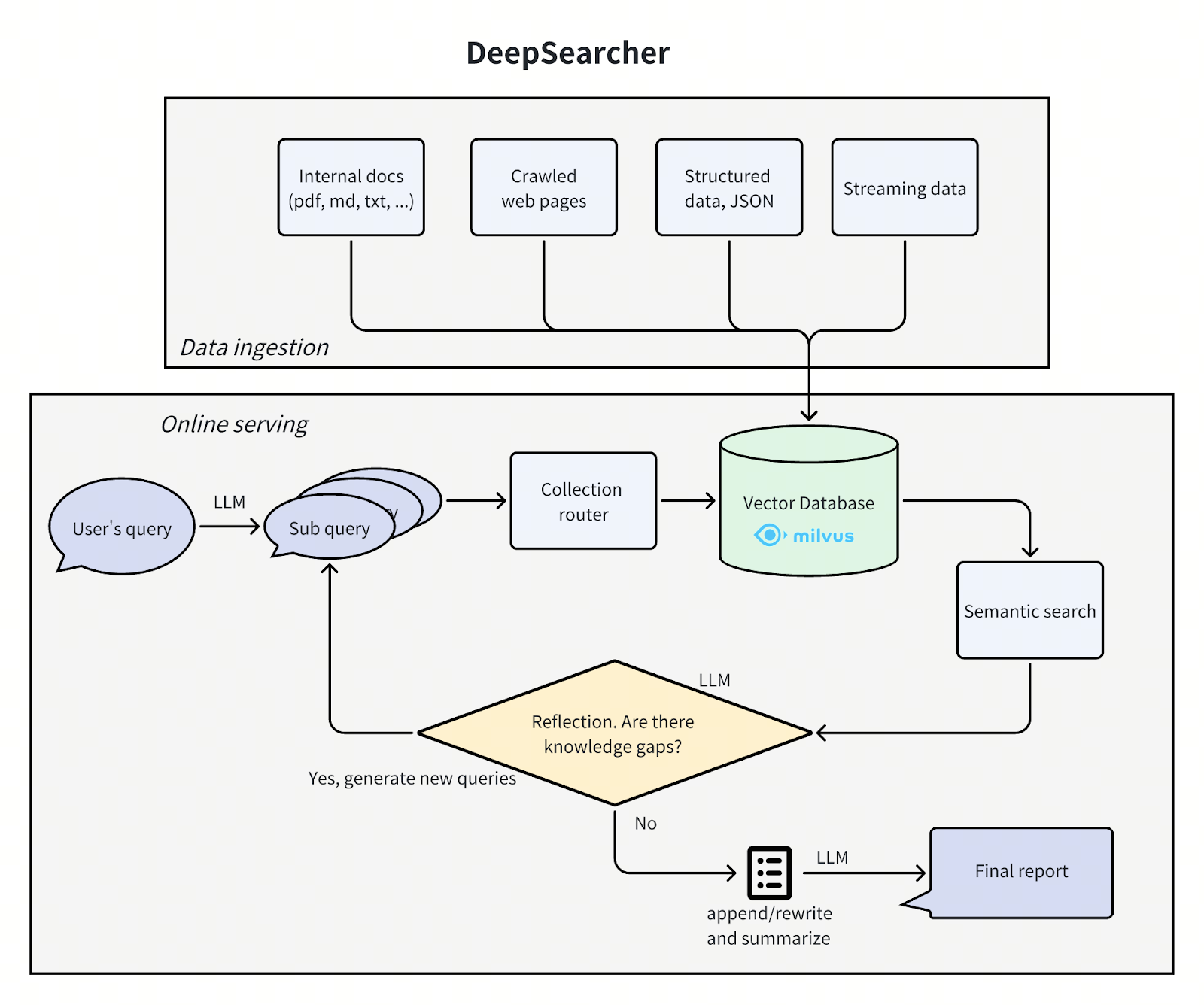 deepsearcher architecture.png
deepsearcher architecture.png
Definire e affinare la domanda
Scomporre l'interrogazione originale in nuove sotto-interrogazioni: [
Come si è evoluto l'impatto culturale e la rilevanza sociale de I Simpson dal suo debutto a oggi?",
Quali cambiamenti nello sviluppo dei personaggi, nell'umorismo e negli stili di narrazione si sono verificati nelle diverse stagioni dei Simpson?
Come sono cambiati nel tempo lo stile di animazione e la tecnologia di produzione dei Simpson?
Come sono cambiati i dati demografici, la ricezione e gli ascolti del pubblico de I Simpson nel corso della sua storia?"].
Nel progetto di DeepSearcher, i confini tra la ricerca e l'affinamento della domanda sono sfumati. La domanda iniziale dell'utente viene scomposta in sotto-query, come nel post precedente. Si vedano le sottoquery iniziali prodotte dalla domanda "Come sono cambiati i Simpson nel corso del tempo? Tuttavia, la fase di ricerca successiva continuerà a perfezionare la domanda secondo le necessità.
Ricerca e analisi
Dopo aver suddiviso la query in sotto-query, inizia la parte di ricerca dell'agente. Si tratta, grosso modo, di quattro fasi: indirizzamento, ricerca, riflessione e ripetizione condizionale.
Instradamento
Il nostro database contiene più tabelle o raccolte di fonti diverse. Sarebbe più efficiente se potessimo restringere la nostra ricerca semantica solo a quelle fonti che sono rilevanti per l'interrogazione in questione. Un router di query chiede a un LLM di decidere da quali collezioni recuperare le informazioni.
Ecco il metodo per formare la richiesta di instradamento della query:
def get_vector_db_search_prompt(
domanda: str,
nomi_raccolta: Lista[str],
descrizioni_della_raccolta: Elenco[str],
contesto: Elenco[str] = Nessuno,
):
sezioni = []
# prompt comune
common_prompt = f"""Sei un analista avanzato di problemi di intelligenza artificiale. Usa la tua capacità di ragionamento e le informazioni storiche sulle conversazioni, basate su tutti i set di dati esistenti, per ottenere risposte assolutamente accurate alle seguenti domande e genera una domanda adatta per ogni set di dati in base alla descrizione del set di dati che può essere correlato alla domanda.
Domanda: {domanda}
"""
sections.append(common_prompt)
# prompt dell'insieme di dati
insieme_dati = []
per i, nome_collezione in enumerate(nomi_collezione):
data_set.append(f"{nome_collezione}: {descrizioni_collezione[i]}")
data_set_prompt = f"""Di seguito sono riportate tutte le informazioni sul set di dati. Il formato delle informazioni sul set di dati è Nome del set di dati: Descrizione del set di dati.
Set di dati e descrizioni:
"""
sections.append(data_set_prompt + "\n".join(data_set))
# richiesta di contesto
se contesto:
context_prompt = f"""Quella che segue è una versione condensata della conversazione storica. Queste informazioni devono essere combinate in questa analisi per generare domande più vicine alla risposta. Non è possibile generare domande uguali o simili per lo stesso set di dati, né rigenerare domande per set di dati che sono stati determinati come non correlati.
Conversazione storica:
"""
sections.append(context_prompt + "\n".join(context))
# prompt di risposta
response_prompt = f"""Sulla base di quanto sopra, è possibile selezionare solo alcuni set di dati dal seguente elenco di set di dati per generare domande correlate appropriate per i set di dati selezionati, al fine di risolvere i problemi di cui sopra. Il formato di output è json, dove la chiave è il nome del set di dati e il valore è la domanda generata corrispondente.
Insiemi di dati:
"""
sections.append(response_prompt + "\n".join(collection_names))
footer = """Rispondere esclusivamente in un formato JSON valido che corrisponde allo schema JSON esatto.
Requisiti critici:
- Includere UN SOLO tipo di azione
- Non aggiungere mai chiavi non supportate
- Escludere tutto il testo, il markdown o le spiegazioni non JSON.
- Mantenere una rigorosa sintassi JSON"""
sections.append(footer)
return "\n\n".join(sezioni)
Facciamo in modo che LLM restituisca un output strutturato come JSON, in modo da convertire facilmente il suo output in una decisione su cosa fare successivamente.
Ricerca
Avendo selezionato varie raccolte di database tramite il passo precedente, la fase di ricerca esegue una ricerca di similarità con Milvus. Come nel caso del post precedente, i dati di partenza sono stati specificati in anticipo, suddivisi in chunk, incorporati e memorizzati nel database vettoriale. Per DeepSearcher, le fonti di dati, sia locali che online, devono essere specificate manualmente. Lasciamo la ricerca online per un lavoro futuro.
Riflessione
A differenza del post precedente, DeepSearcher illustra una vera e propria forma di riflessione agenziale, inserendo i risultati precedenti come contesto in un prompt che "riflette" se le domande poste finora e i relativi pezzi recuperati contengono lacune informative. Questa può essere vista come una fase di analisi.
Ecco il metodo per creare il prompt:
def get_reflect_prompt(
domanda: str,
mini_domande: Lista[str],
mini_chuncks: Elenco[str],
):
mini_chunk_str = ""
per i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
reflect_prompt = f"""Determinare se sono necessarie ulteriori query di ricerca in base alla query originale, alle precedenti sotto-query e a tutti i chunk di documenti recuperati. Se sono necessarie ulteriori ricerche, fornire un elenco Python con un massimo di 3 query di ricerca. Se non sono necessarie ulteriori ricerche, restituire un elenco vuoto.
Se la query originale è per scrivere un report e si preferisce generare altre query, restituire un elenco vuoto.
Query originale: {domanda}
Query secondarie precedenti: {mini_domande}
Pezzi correlati:
{mini_chunk_str}
"""
footer = """Rispondere esclusivamente nel formato List of str valido senza altro testo."""
return reflect_prompt + footer
Ancora una volta, facciamo in modo che LLM restituisca un output strutturato, questa volta come dati interpretabili da Python.
Ecco un esempio di nuove sotto-query "scoperte" dalla riflessione dopo aver risposto alle sotto-query iniziali di cui sopra:
Nuove query di ricerca per la prossima iterazione: [
"In che modo i cambiamenti nel cast vocale e nel team di produzione dei Simpson hanno influenzato l'evoluzione dello show nel corso delle diverse stagioni?",
"Che ruolo hanno avuto la satira e i commenti sociali dei Simpson nel loro adattamento a temi contemporanei attraverso i decenni?",
Come i Simpson hanno affrontato e incorporato i cambiamenti nel consumo dei media, come i servizi di streaming, nelle loro strategie di distribuzione e di contenuto?"].
Ripetizione condizionale
A differenza del nostro post precedente, DeepSearcher illustra un flusso di esecuzione condizionale. Dopo aver riflettuto se le domande e le risposte ottenute finora sono complete, se ci sono altre domande da porre l'agente ripete i passaggi precedenti. È importante notare che il flusso di esecuzione (un ciclo while) è una funzione dell'output di LLM, anziché essere codificato. In questo caso c'è solo una scelta binaria: ripetere la ricerca o generare un rapporto. In agenti più complessi possono essercene diverse, come ad esempio: seguire un collegamento ipertestuale, recuperare pezzi, immagazzinare in memoria, riflettere, ecc. In questo modo, la domanda continua a essere perfezionata come l'agente ritiene opportuno, finché non decide di uscire dal ciclo e generare il rapporto. Nel nostro esempio dei Simpson, DeepSearcher esegue altri due cicli di riempimento dei vuoti con sotto-query aggiuntive.
Sintetizza
Infine, la domanda completamente scomposta e i pezzi recuperati vengono sintetizzati in un report con un singolo prompt. Ecco il codice per creare il prompt:
def get_final_answer_prompt(
domanda: str,
mini_domande: Lista[str],
mini_chuncks: Elenco[str],
):
mini_chunk_str = ""
per i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""Sei un esperto di analisi dei contenuti dell'intelligenza artificiale, bravo a riassumere i contenuti. Ti preghiamo di riassumere una risposta o un rapporto specifico e dettagliato sulla base delle query precedenti e dei chunk di documenti recuperati.
Domanda originale: {domanda}
Query secondarie precedenti: {mini_questioni}
Pezzi correlati:
{mini_chunk_str}
"""
restituire summary_prompt
Questo approccio ha il vantaggio, rispetto al nostro prototipo che analizzava ogni domanda separatamente e si limitava a concatenare i risultati, di produrre un report in cui tutte le sezioni sono coerenti tra loro, cioè non contengono informazioni ripetute o contraddittorie. Un sistema più complesso potrebbe combinare aspetti di entrambi, utilizzando un flusso di esecuzione condizionale per strutturare il report, riassumere, riscrivere, riflettere e fare pivot, e così via.
Risultati
Ecco un esempio del report generato dalla query "Come sono cambiati i Simpson nel tempo?" con DeepSeek-R1 che passa la pagina di Wikipedia sui Simpson come materiale di partenza:
Rapporto: L'evoluzione dei Simpson (1989-oggi)
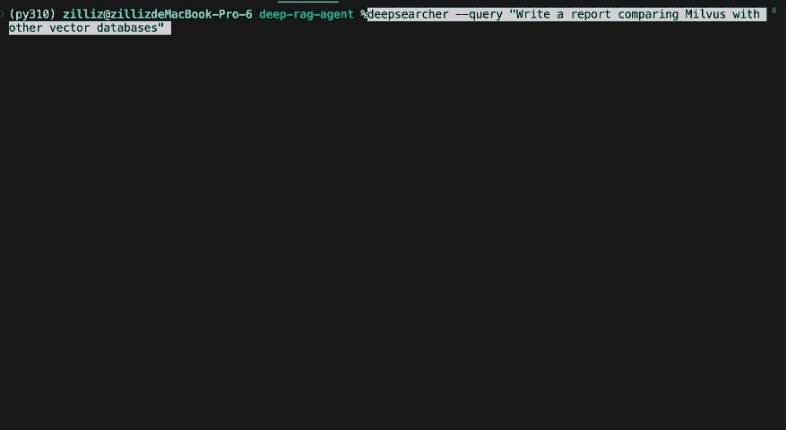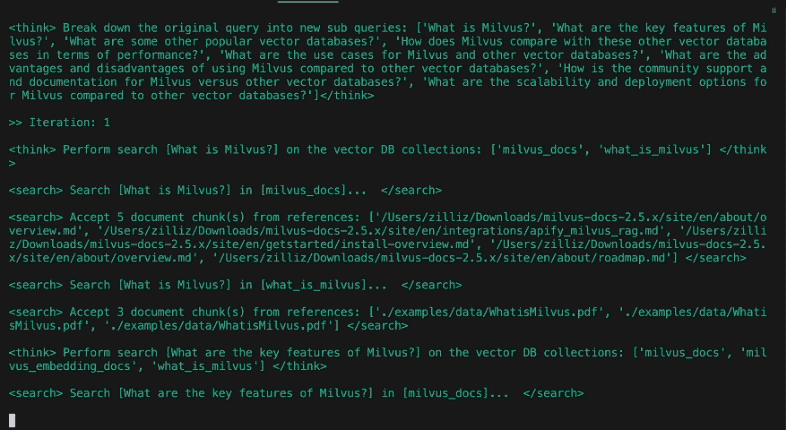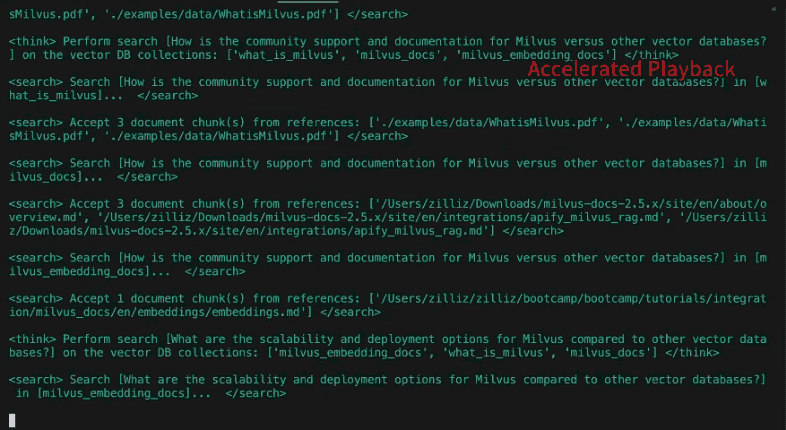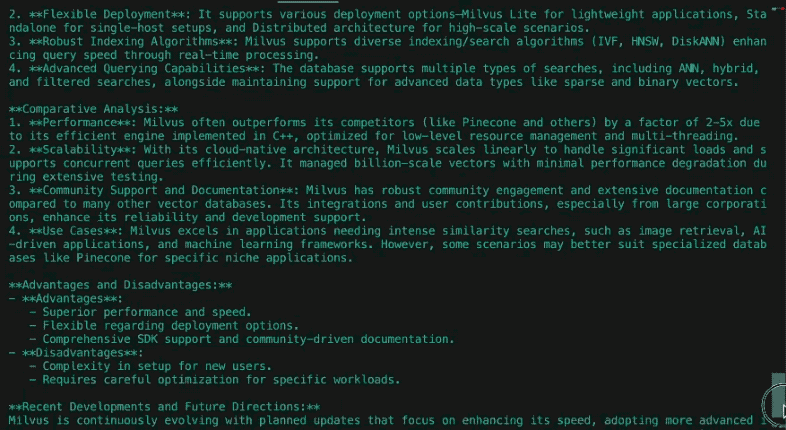
1. Impatto culturale e rilevanza sociale
I Simpson hanno debuttato come critica sovversiva della vita della classe media americana, guadagnando notorietà per la sua satira audace negli anni Novanta. Inizialmente un fenomeno controculturale, ha sfidato le norme con episodi che affrontavano la religione, la politica e il consumismo. Nel corso del tempo, il suo dominio culturale è andato scemando, mentre concorrenti come South Park e Family Guy si sono spinti oltre. Negli anni 2010, lo show si è trasformato da trendsetter a istituzione nostalgica, bilanciando il fascino del passato con i tentativi di affrontare temi moderni come il cambiamento climatico e i diritti LGBTQ+, anche se con minore risonanza sociale.
...
Conclusione
I Simpson si sono evoluti da satira radicale a istituzione televisiva, attraversando i cambiamenti della tecnologia, della politica e delle aspettative del pubblico. Mentre la sua brillantezza dell'epoca d'oro rimane ineguagliata, la sua adattabilità - attraverso lo streaming, l'umorismo aggiornato e la diffusione globale - ne fa una pietra di paragone culturale. La longevità dello show riflette sia la nostalgia che l'accettazione pragmatica del cambiamento, anche se è alle prese con le sfide della rilevanza in un panorama mediatico frammentato.
Trovate [il rapporto completo qui] (https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view?usp=sharing) e [un rapporto prodotto da DeepSearcher con GPT-4o mini] (https://drive.google.com/file/d/1EGd16sJDNFnssk9yTd5o9jzbizrY_NS_/view?usp=sharing) per un confronto.
Discussione
Abbiamo presentato DeepSearcher, un agente che esegue ricerche e scrive relazioni. Il nostro sistema si basa sull'idea del nostro precedente articolo, aggiungendo caratteristiche come il flusso di esecuzione condizionale, l'instradamento delle query e un'interfaccia migliorata. Siamo passati dall'inferenza locale con un piccolo modello di ragionamento quantizzato a 4 bit a un servizio di inferenza online per il modello massivo DeepSeek-R1, migliorando qualitativamente il nostro rapporto di output. DeepSearcher funziona con la maggior parte dei servizi di inferenza come OpenAI, Gemini, DeepSeek e Grok 3 (in arrivo!).
I modelli di ragionamento, in particolare quelli utilizzati negli agenti di ricerca, sono molto ricchi di inferenza e noi abbiamo avuto la fortuna di poter utilizzare l'offerta più veloce di DeepSeek-R1 di SambaNova, in esecuzione sul loro hardware personalizzato. Per la nostra query dimostrativa, abbiamo effettuato sessantacinque chiamate al servizio di inferenza DeepSeek-R1 di SambaNova, inserendo circa 25k token, producendo 22k token e spendendo 0,30 dollari. Siamo rimasti impressionati dalla velocità di inferenza, dato che il modello contiene 671 miliardi di parametri ed è grande 3/4 di terabyte. Maggiori dettagli qui!
Continueremo ad approfondire questo lavoro nei prossimi post, esaminando altri concetti agenziali e lo spazio di progettazione degli agenti di ricerca. Nel frattempo, invitiamo tutti a provare DeepSearcher, a stellarci su GitHub e a condividere il vostro feedback!
Risorse

Continua a leggere

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.