




Databricks & Spark Connectors
Leverage Databricks' powerful data processing alongside Milvus & Zilliz Cloud's vector index and search with no custom code required
Utilisez cette intégration gratuitement
Combiner le traitement des données avec les capacités de recherche vectorielle de Milvus & Zilliz Cloud
Databricks est une plateforme d’analyse unifiée qui simplifie les tâches de traitement des données et d’apprentissage automatique. Elle est construite sur Apache Spark, un système de calcul distribué open source. Elle fournit un environnement collaboratif permettant aux ingénieurs de données, aux scientifiques des données et aux analystes de collaborer sur des projets Big Data. Databricks fait abstraction des complexités liées à la gestion des clusters Spark, permettant aux utilisateurs de se concentrer sur les tâches d’analyse des données et d’apprentissage automatique. Elle propose des notebooks interactifs, une gestion automatisée des clusters et une prise en charge intégrée de diverses sources de données et bibliothèques d’apprentissage automatique. Dans l’ensemble, Databricks améliore l’utilisabilité et l’évolutivité de Spark, facilitant ainsi l’obtention d’insights à partir de grands jeux de données pour les organisations.
Le connecteur Spark Milvus crée des synergies entre Apache Spark et Milvus, permettant aux utilisateurs d’exploiter les capacités de traitement de Spark ainsi que les fonctionnalités de stockage et de requête de données vectorielles de Milvus. Cette intégration ouvre la voie à une gamme d’applications précieuses, telles que le transfert et l’intégration transparents de données entre Milvus et différents systèmes de stockage ou bases de données, le traitement et l’analyse rationalisés des données au sein de Milvus, ainsi que des opérations efficaces de traitement vectoriel exploitant Spark MLlib et d’autres bibliothèques d’IA.
Ce même connecteur peut être utilisé entre Zilliz Cloud et Databricks, simplifiant la transition des données du traitement hors ligne vers l’environnement en ligne, ce qui est important pour la recherche pilotée par l’IA.
Les principaux points forts de l’intégration incluent :
- Permettre aux jobs Spark générant des vecteurs de charger des données directement dans Milvus via un simple appel à une fonction utilitaire, éliminant ainsi le besoin de code d’intégration personnalisé ou de jobs Spark supplémentaires
- Insérer directement les enregistrements Spark DataFrame dans Milvus à l’aide du connecteur Spark-Milvus rationalise l’intégration, éliminant le besoin de code d’établissement de connexion et d’appels API.
Comment ça fonctionne
Plongeons dans le processus de transfert de données de Spark vers Milvus. Traditionnellement, cette tâche nécessitait un code de liaison backend complexe. Cependant, avec le connecteur Spark-Milvus, elle est simplifiée en un seul appel de fonction au sein de votre application Spark.
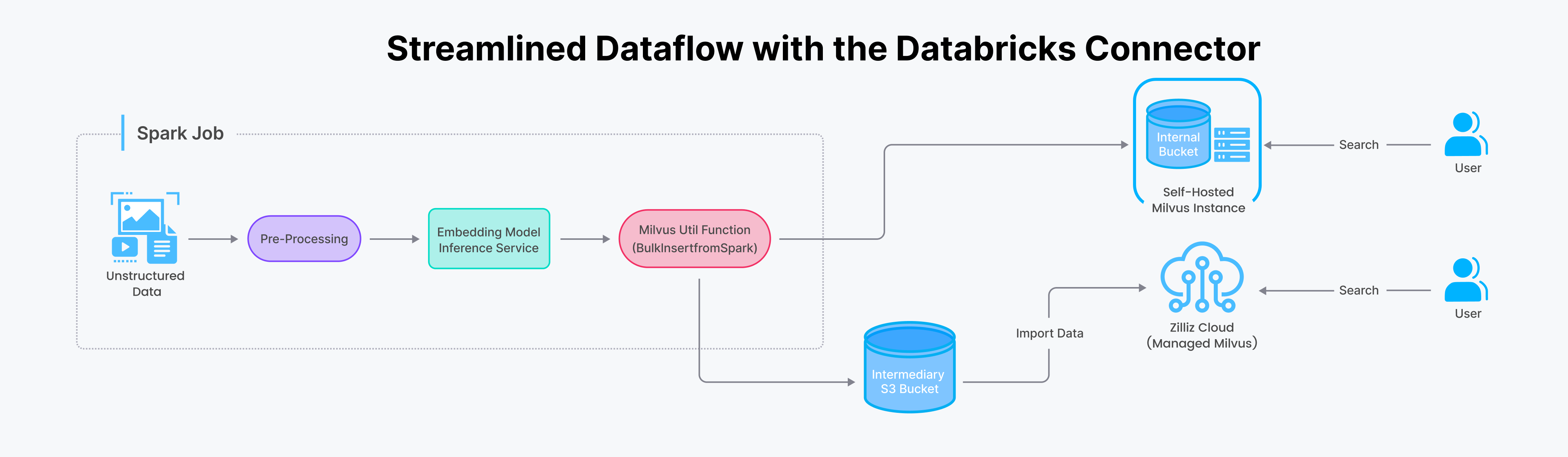 Flux de données simplifié avec le connecteur Databricks.png
Flux de données simplifié avec le connecteur Databricks.png
Avec le connecteur Spark/Databricks, vous pouvez importer des données vers Zilliz Cloud (ou Milvus) de deux façons : en streaming pour les mises à jour en temps réel et par lots pour les grands ensembles de données. Consultez nos exemples de notebooks pour un guide étape par étape sur la façon de l’utiliser efficacement.
Découvrez comment utiliser les connecteurs Sparks et Databricks
Consultez ces ressources pour vous aider à commencer à utiliser Zilliz Cloud, les connecteurs Spark et Databricks
Connecteur Spark Milvus
Connecteur Databricks