




Read AI met à l’échelle l’intelligence conversationnelle avec Milvus pour des millions d’utilisateurs actifs

Inférieur à 20-50 ms
latence de récupération pour des millions d’utilisateurs mensuels
Accélération 5×
dans la recherche agentique
À l’échelle du million
prise en charge des locataires actifs
Expérience utilisateur améliorée
en favorisant le passage d’une recherche réactive à une recherche proactive
We've got millions of monthly active users and all of the underlying data when we're trying to go find related conversations, find updates to an action item, find referenced documents...Milvus serves as the central repository and powers our information retrieval among billions of records.
Rob Williams
Résumé exécutif
Read AI avait besoin d’une base de données vectorielle haute performance pour prendre en charge la recherche à l’échelle de l’entreprise dans des sources de communication non structurées, notamment les réunions, les discussions, les e-mails et les bases de connaissances internes. En adoptant Milvus comme socle de son infrastructure de recherche sémantique, Read AI a pu indexer et interroger à grande échelle des embeddings riches en narration, permettant une recherche rapide et précise dans des milliards d’enregistrements.
Latence de recherche inférieure à 20-50 ms pour des millions d’utilisateurs mensuels
Hautement évolutif pour gérer des millions de locataires actifs
Gains majeurs de productivité pour les développeurs
« Nous avons des millions d’utilisateurs actifs mensuels et toutes les données sous-jacentes lorsque nous essayons de trouver des conversations connexes, des mises à jour d’un élément d’action, des documents référencés... Milvus sert de référentiel central et alimente notre recherche d’informations parmi des milliards d’enregistrements. »--Rob Williams, cofondateur et CTO chez Read AI
À propos de Read AI
Read AI est une entreprise d’IA de productivité de premier plan qui aide des millions de personnes à consacrer davantage de temps au travail qui compte le plus. Initialement axée sur la réduction de la fatigue liée aux réunions, l’entreprise a évolué pour devenir une plateforme d’intelligence full-stack qui propose également des prochaines étapes prédictives, une recherche d’entreprise et un coaching en temps réel, s’intégrant parfaitement aux outils de calendriers (Google Calendar, Outlook 365, Zoom Calendar), de CRM (Salesforce, HubSpot), de plateformes de collaboration (Jira, Confluence, Notion), d’applications de messagerie (Slack, Microsoft Teams), d’outils de prise de notes (Google Docs, OneNote), d’e-mail (Gmail, Outlook) et de visioconférence (Zoom, Google Meet, Microsoft Teams). Elle ingère et contextualise les données issues de ces sources, transformant les interactions passives en récits structurés, interrogeables et exploitables.
Conçu avec une approche axée d’abord sur le consommateur, Read AI prend en charge des millions d’utilisateurs via un modèle en libre-service, fonctionnant à une véritable échelle Internet avec des milliards d’événements de conversation traités au sein d’innombrables entreprises.
Le défi technique
En raison de sa croissance fulgurante, Read AI a été confronté à un défi fondamental : organiser et retrouver des données de communication non structurées issues d’un large éventail de sources — des réunions et discussions aux mises à jour CRM, calendriers, fils d’e-mails et tickets d’assistance. Chaque source contient des signaux précieux, mais reste cloisonnée, manque de structure cohérente et est difficile à rechercher efficacement. L’objectif : fournir des résultats intelligents et contextuels dans les 20 minutes suivant toute interaction.
Cela nécessitait une ingestion, une transformation et une indexation des données quasi en temps réel dans divers formats. Des réunions internes bien structurées aux plateformes tierces plus éparses comme Slack, Gmail et HubSpot. À mesure que l’utilisation augmentait, Read AI devait prendre en charge des milliards d’enregistrements sur des millions de locataires, des milliers de requêtes par seconde et une latence inférieure à 20 - 50 ms. Les solutions précédentes, notamment des magasins développés en interne et d’autres bases de données vectorielles comme Pinecone et Faiss, n’ont pas répondu à ces exigences en raison d’une mauvaise prise en charge du multi-tenant, de capacités de filtrage limitées ou d’un manque de réactivité de la communauté.
L’architecture de solution avec Milvus
La nouvelle architecture de Read AI est conçue pour gérer une recherche à haut débit et faible latence dans diverses sources de communication comme Slack, Zoom, l’e-mail et Salesforce. Ces entrées passent par une couche d’embedding et de narration qui transforme les données brutes en récits structurés et en représentations sensibles au sentiment. Tout est stocké dans la base de données vectorielle Milvus, qui sert efficacement de référentiel central pour les informations.
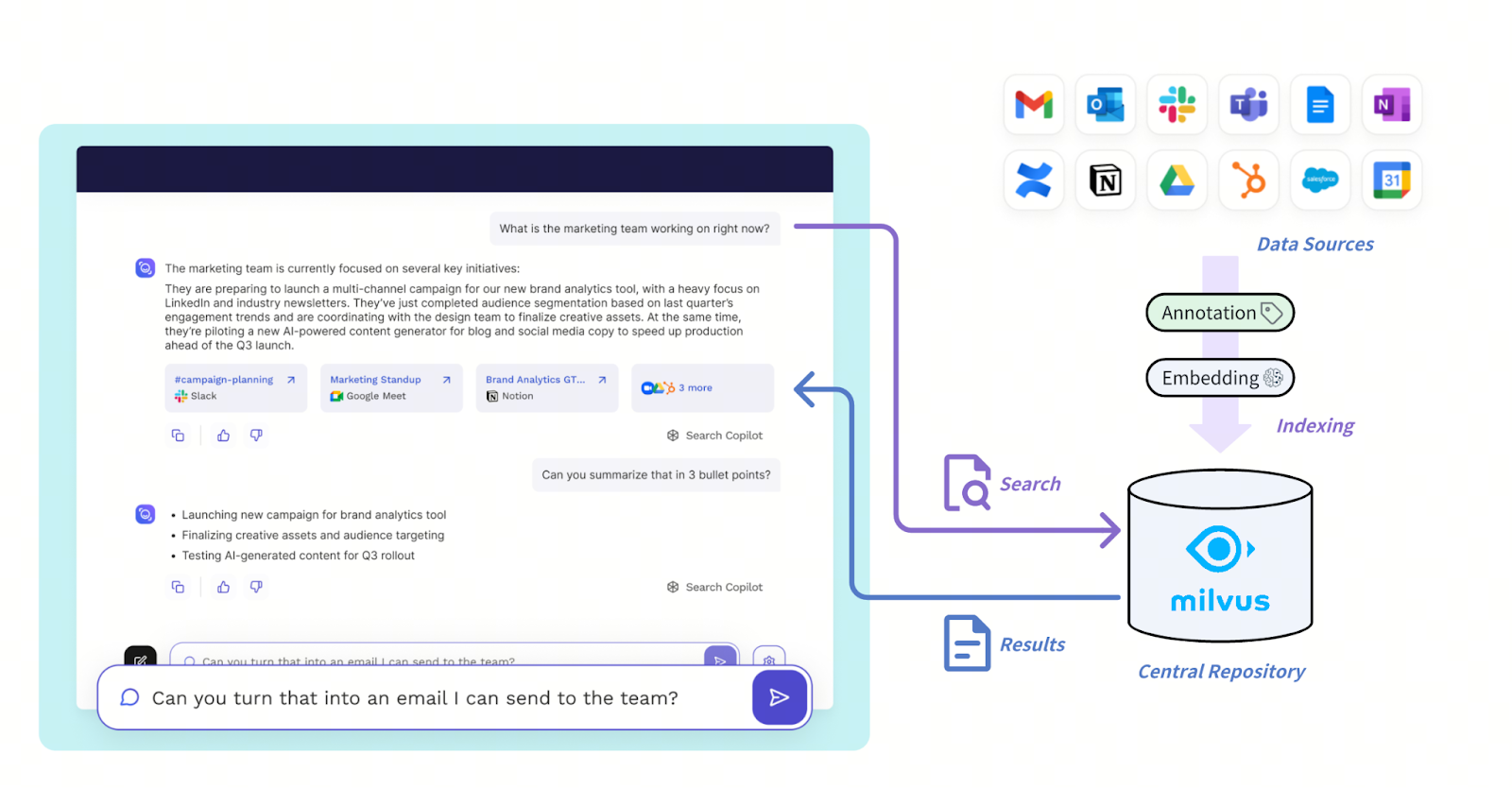 L’architecture de solution avec Milvus
L’architecture de solution avec Milvus
Figure : Comment Mivus prend en charge le système Read AI
Read AI utilise une recherche vectorielle filtrée qui combine la similarité vectorielle avec un filtrage basé sur des métadonnées structurées, par exemple en limitant les requêtes aux réunions en tête-à-tête, à des employés spécifiques ou à des fenêtres temporelles, permettant ainsi une récupération nuancée comme « appels commerciaux les plus désengagés » ou « retours positifs lors de tête-à-tête ». Le filtrage optimisé des métadonnées de Milvus est crucial pour atteindre une latence inférieure à 20-50 ms à cette échelle.
« Milvus nous offre une couche de stockage sensible au récit — pas seulement des embeddings de texte, mais une recherche pleinement sensible au contexte. » — Rob Williams, cofondateur et CTO chez Read AI
Grâce à la prise en charge native de la multi-tenance dans Milvus, Read AI déploie un seul cluster Milvus pour servir efficacement des millions de tenants. Les requêtes sont orchestrées via des frameworks d’agents internes qui analysent l’intention de recherche et acheminent les demandes vers Milvus, puis post-traitent les résultats pour les livrer via des interfaces de chat, des résumés ou des alertes. Cette architecture donne à Read AI l’évolutivité et la flexibilité nécessaires pour unifier des types de contenus disparates tout en maintenant vitesse et précision, essentielles à la récupération en temps réel et à l’analyse rétrospective.
Évaluation technique et processus de décision
Avant d’adopter Milvus, l’équipe de Read AI a évalué plusieurs alternatives. FAISS a été écarté en raison de son absence de multi-tenance intégrée et de ses capacités de filtrage limitées. Pinecone n’offrait pas la flexibilité nécessaire pour prendre en charge le modèle de recherche et l’échelle de Read AI. Une solution entièrement auto-hébergée et développée en interne a également été envisagée, mais elle ne pouvait pas répondre aux exigences d’évolutivité et de maturité de leur cas d’utilisation. Milvus s’est distingué sur la base de plusieurs facteurs clés :
La capacité à évoluer jusqu’à des millions d’utilisateurs et des milliards d’enregistrements
Une latence constamment inférieure à 20-50 ms sur de grandes collections vectorielles
La prise en charge des workflows de recherche hybride
L’isolation au niveau des tenants
L’expérience développeur a été un autre facteur décisif, avec une documentation claire, des mainteneurs réactifs et un support d’ingénierie pratique, en particulier pendant leur preuve de concept. La phase de PoC a démontré un délai d’exécution rapide sur les charges de test et fourni une assistance au débogage en temps réel de la part de l’équipe Milvus, ce qui a donné à Read AI la confiance nécessaire pour passer en production.
Résultats et avantages du choix de Milvus
Depuis le déploiement de Milvus et parallèlement au lancement par l’entreprise de son outil de recherche d’entreprise Search Copilot, Read AI a obtenu une accélération par 5 de la recherche agentique sur diverses sources de données, en maintenant une latence de récupération constante d’environ 20 à 50 ms, même lors du traitement de requêtes avec des filtres complexes. La plateforme a intégré en douceur des millions de comptes d’utilisateurs individuels dans un cluster géant sans interruption, démontrant la robustesse de l’architecture distribuée de Milvus et de sa capacité de multi-tenance.
Milvus alimente une couche de recherche unifiée sur tous les canaux de communication—réunions, chat, e-mail et CRM. La mise à l’échelle élastique simplifie les opérations pour gérer des cohortes d’entreprise ou des pics de trafic. Des fonctionnalités comme l’importation en masse offrent une expérience fluide lors de l’intégration de grandes quantités de données historiques à mesure que de nouvelles entreprises s’inscrivent au service.
Plus important encore, Milvus permet de passer d’une recherche réactive à une recherche proactive : faire émerger des insights, des actions à réaliser et des risques pertinents avant même que les utilisateurs ne les demandent, grâce à une recherche vectorielle à faible latence sur des contextes dynamiques et multimodaux. Cette capacité améliore non seulement l’expérience utilisateur, mais ouvre également de nouvelles opportunités commerciales alors que Read AI continue de se concentrer sur l’expansion de la plateforme avec des avancées continues en matière de recommandations prédictives et de prochaines étapes.
« Ce que nous voulions, c’était apporter l’intelligence à l’utilisateur avant même qu’il ne la demande. Milvus est ce qui a rendu cela viable. » —Rob Williams, cofondateur et CTO chez Read AI
Ces gains techniques se traduisent directement en valeur commerciale : les utilisateurs de l’offre gratuite reçoivent des insights significatifs en quelques minutes, ce qui stimule la rétention, tandis que les clients entreprise bénéficient d’une récupération de connaissances plus approfondie et d’un contexte à long terme, renforçant la confiance des utilisateurs et soutenant les opportunités de montée en gamme premium.
Insights pour développeurs et ingénieurs
Leçons tirées de la mise en œuvre :
L’annotation structurée peut alimenter des sorties LLM en aval plus riches
La recherche vectorielle doit maintenir sa vitesse, même avec un filtrage par métadonnées structurées, afin de préserver l’expérience utilisateur de recherche
L’isolation multi-tenant et la mise à l’échelle dynamique sont non négociables à l’échelle grand public
L’équipe mène des expérimentations continues, en suivant les performances des requêtes, la satisfaction des utilisateurs et les métriques comportementales afin d’affiner en permanence la manière dont les agents recherchent, filtrent et classent les résultats.
Read AI traite les données conversationnelles non seulement avec des modèles d’embedding, mais aussi avec une couche de narration unique. Cette abstraction sémantique va au-delà des transcriptions pour capturer le ton, l’intention et les événements clés comme la progression d’une transaction ou la baisse d’engagement. Ainsi, les utilisateurs peuvent rechercher des récits en langage naturel, tels que « qui était désengagé pendant la démo », plutôt que de simplement faire correspondre des mots-clés.
Feuille de route
Pour l’avenir, Read AI se concentre sur l’amélioration de l’équilibre entre les charges de travail en temps réel et hors ligne, avec des plans visant à créer une orchestration plus dynamique entre les données de streaming en direct et le stockage à plus long terme. L’entreprise explore l’utilisation du prochain Vector Lake de Milvus pour réduire les coûts de recherche en déplaçant les requêtes hors ligne aux attentes de latence assouplies vers une couche de type entrepôt soutenue par du stockage objet.
Un autre domaine clé de développement est la détection automatisée des lacunes de connaissances — identifier quand des informations critiques sont manquantes ou déconnectées — et faire remonter proactivement des insights aux utilisateurs avant même qu’ils ne les demandent. Toutes ces améliorations soutiennent la vision à long terme de Read AI : construire un « moteur d’action » pour l’entreprise — une plateforme alimentée par l’IA, contextuelle et toujours active, qui donne intelligemment plus de moyens aux travailleurs du savoir sur tous les canaux de communication.
En stockant le contexte conversationnel et les insights historiques dans Milvus, Read AI étend la disponibilité des connaissances institutionnelles, faisant remonter les informations critiques même lorsque le participant d’origine est hors ligne ou n’est plus dans l’entreprise.
Conclusion
Le parcours de Read AI, d’un outil d’analyse de réunions à une plateforme d’intelligence à grande échelle destinée au plus grand nombre, exigeait une infrastructure capable de gérer une échelle massive, des données hétérogènes et des exigences de requêtes complexes en temps réel. Milvus s’est révélé être le bon choix — non seulement pour ses performances brutes et sa scalabilité, mais aussi pour sa flexibilité dans la prise en charge des embeddings annotés, du filtrage par métadonnées et de l’isolation multi-tenant.
Avec Milvus comme fondation de son infrastructure de recherche vectorielle, Read AI fournit des résultats et des recommandations rapides, fiables et profondément contextuels à des millions d’utilisateurs. À mesure que l’entreprise progresse vers la construction d’un moteur d’action intelligent et toujours actif pour l’entreprise, Milvus continue de répondre à ses besoins en matière de rentabilité, de flexibilité architecturale et de mise à l’échelle pérenne, prouvant qu’une base de données vectorielle bien conçue est plus qu’un simple stockage ; c’est l’épine dorsale de la compréhension moderne de l’information.
What we wanted was to push intelligence to the user before they even asked. Milvus is what made that viable.
Rob Williams