




Présentation de DeepSearcher : Une source ouverte locale pour la recherche en profondeur
 deep researcher.gif
deep researcher.gif
Dans l'article précédent, "I Built a Deep Research with Open Source-and So Can You !", nous avons expliqué certains des principes qui sous-tendent les agents de recherche et construit un prototype simple qui génère des rapports détaillés sur un sujet ou une question donné(e). L'article et le carnet de notes correspondant ont démontré les concepts fondamentaux d'utilisation d'outils, de composition de requête, de raisonnement et de réflexion. L'exemple présenté dans notre précédent article, contrairement à Deep Research d'OpenAI, a été exécuté localement, en utilisant uniquement des modèles et des outils open-source tels que [Milvus] (https://milvus.io/docs) et LangChain. (Je vous encourage à lire l'article ci-dessus avant de continuer).
Dans les semaines qui ont suivi, l'intérêt pour la compréhension et la reproduction de la Deep Research d'OpenAI a explosé. Voir, par exemple, Perplexity Deep Research et Hugging Face's Open DeepResearch. Ces outils diffèrent en termes d'architecture et de méthodologie, bien qu'ils partagent le même objectif : effectuer des recherches itératives sur un sujet ou une question en surfant sur le web ou sur des documents internes et produire un rapport détaillé, bien informé et bien structuré. Il est important de noter que l'agent sous-jacent automatise le raisonnement sur les mesures à prendre à chaque étape intermédiaire.
Dans cet article, nous nous appuyons sur notre article précédent et présentons le projet open-source de Zilliz [DeepSearcher] (https://github.com/zilliztech/deep-searcher). Notre agent démontre des concepts supplémentaires : Le routage des requêtes, le flux d'exécution conditionnel et l'exploration du Web en tant qu'outil. Il est présenté comme une bibliothèque Python et un outil de ligne de commande plutôt qu'un carnet Jupyter et est plus complet que notre précédent billet. Par exemple, il peut entrer plusieurs documents sources et peut définir le modèle d'intégration et la base de données vectorielle utilisés via un fichier de configuration. Bien qu'il soit encore relativement simple, DeepSearcher est une excellente vitrine du RAG agentique et constitue un pas de plus vers des applications d'IA de pointe.
En outre, nous explorons le besoin de services d'inférence plus rapides et plus efficaces. Les modèles de raisonnement utilisent "l'échelle d'inférence", c'est-à-dire des calculs supplémentaires, pour améliorer leurs résultats, et cela, combiné au fait qu'un seul rapport peut nécessiter des centaines ou des milliers d'appels LLM, fait que la bande passante d'inférence est le principal goulot d'étranglement. Nous utilisons le [modèle de raisonnement DeepSeek-R1 sur le matériel personnalisé de SambaNova] (https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency), qui est deux fois plus rapide en termes de jetons de sortie par seconde que le concurrent le plus proche (voir la figure ci-dessous).
SambaNova Cloud fournit également un service d'inférence pour d'autres modèles open-source, notamment Llama 3.x, Qwen2.5 et QwQ. Le service d'inférence fonctionne sur la puce personnalisée de SambaNova appelée unité de flux de données reconfigurable (RDU), qui est spécialement conçue pour une inférence efficace sur les modèles d'IA générative, réduisant les coûts et augmentant la vitesse d'inférence. [Pour en savoir plus, consultez leur site web] (https://sambanova.ai/technology/sn40l-rdu-ai-chip)
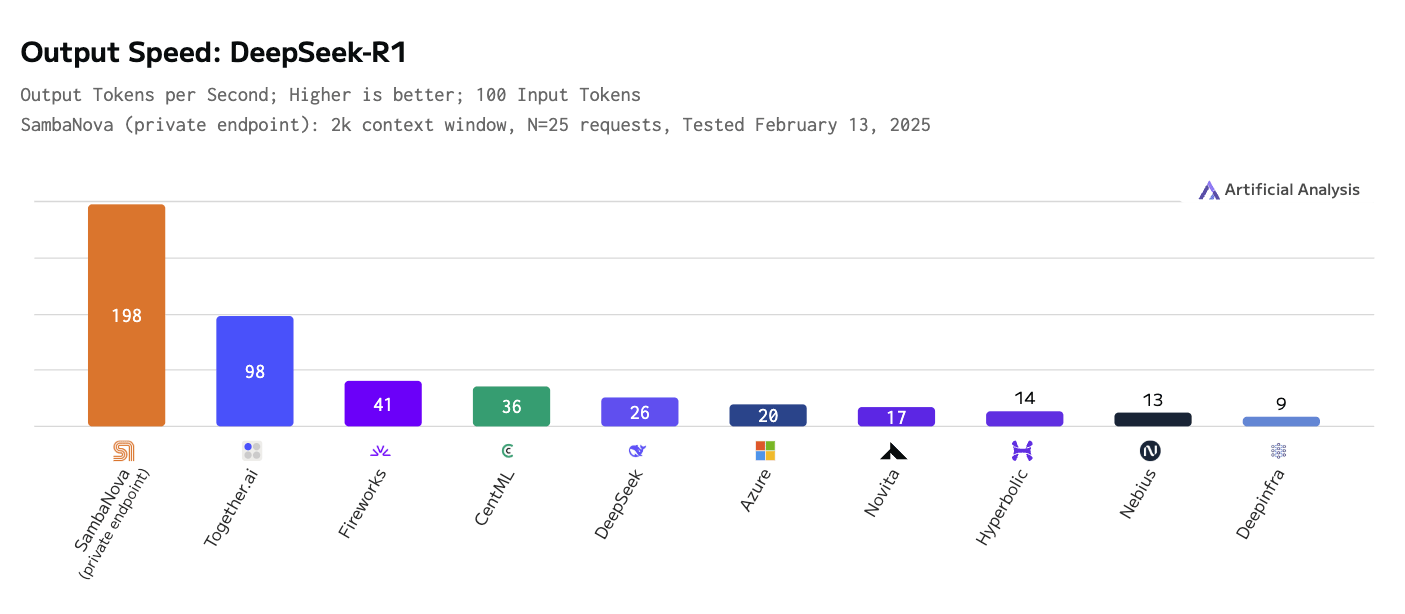 Vitesse de sortie - deepseek r1.png
Vitesse de sortie - deepseek r1.png
Architecture de DeepSearcher
L'architecture de DeepSearcher suit notre précédent billet en décomposant le problème en quatre étapes - définir/affiner la question, rechercher, analyser, synthétiser - bien que cette fois-ci avec quelques chevauchements. Nous passons en revue chaque étape, en soulignant les améliorations apportées par DeepSearcher.
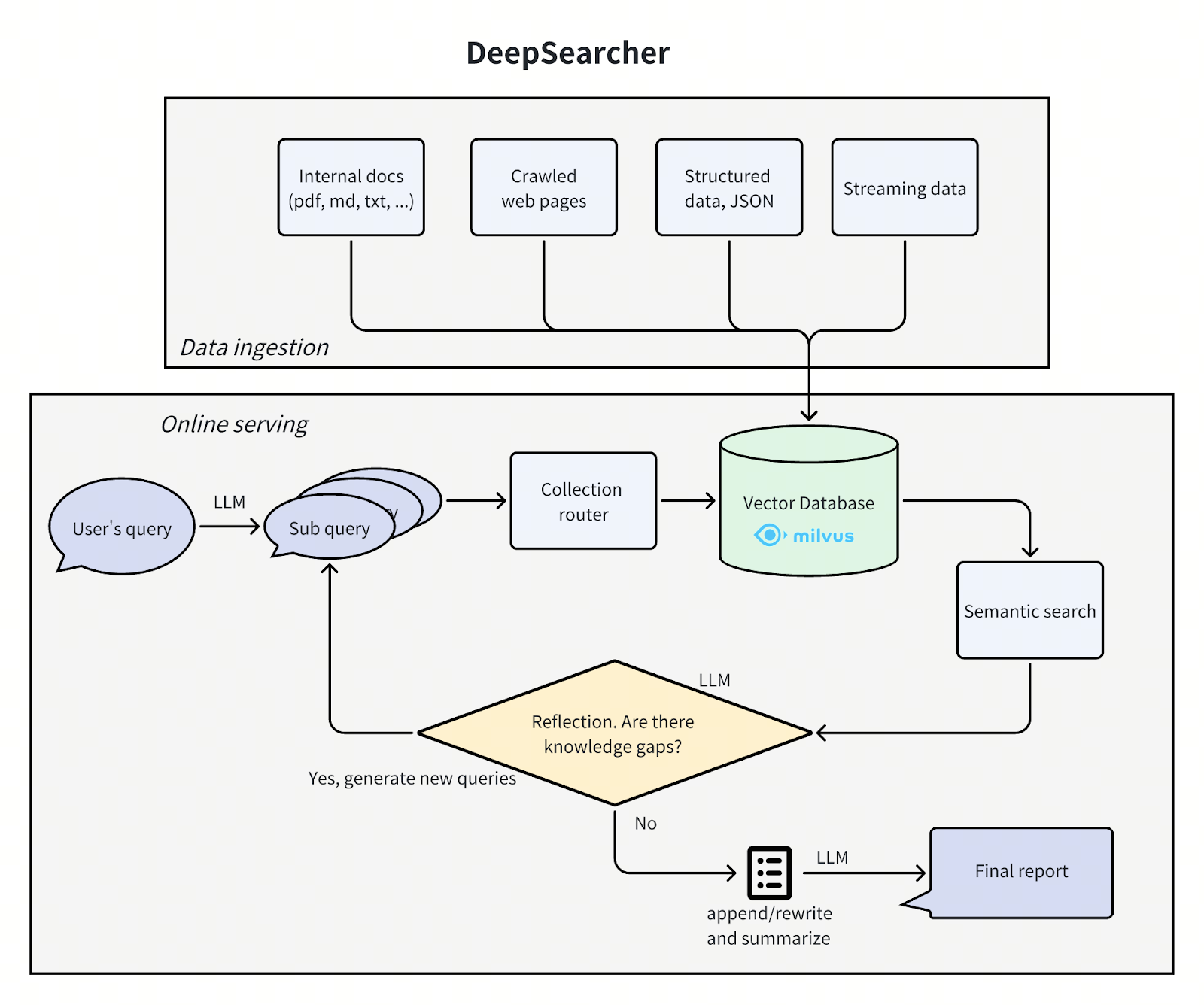 deepsearcher architecture.png
deepsearcher architecture.png
Définir et affiner la question
Décomposer la requête originale en nouvelles sous-requêtes : [
Comment l'impact culturel et la pertinence sociétale des Simpsons ont-ils évolué depuis leurs débuts jusqu'à aujourd'hui ?
Quels changements dans le développement des personnages, l'humour et les styles de narration se sont produits au cours des différentes saisons des Simpson ?
Comment le style d'animation et la technologie de production des Simpson ont-ils évolué au fil du temps ?
Comment la démographie, la réception et l'audience du jeu Les Simpson ont-elles évolué au cours de sa diffusion ?]
Dans la conception de DeepSearcher, les limites entre la recherche et l'affinement de la question sont floues. La requête initiale de l'utilisateur est décomposée en sous-requêtes, à l'instar de l'article précédent. Voir ci-dessus les sous-requêtes initiales produites à partir de la requête "Comment les Simpsons ont-ils changé au fil du temps ? Cependant, l'étape de recherche suivante continuera à affiner la question si nécessaire.
Recherche et analyse
Après avoir décomposé la requête en sous-requêtes, la partie recherche de l'agent commence. Elle comporte, grosso modo, quatre étapes : acheminement, recherche, réflexion et répétition conditionnelle.
Routage
Notre base de données contient plusieurs tables ou collections provenant de différentes sources. Il serait plus efficace de restreindre notre recherche sémantique aux seules sources pertinentes pour la requête en question. Un routeur de requêtes invite un LLM à décider des collections à partir desquelles les informations doivent être récupérées.
Voici la méthode pour former l'invite de routage de requête :
``python def get_vector_db_search_prompt( question : str, collection_names : Liste[str], collection_descriptions : Liste[str], contexte : List[str] = None, ) : sections = [] # invite commune common_prompt = f"""Vous êtes un analyste avancé de problèmes d'IA. Utilisez votre capacité de raisonnement et les informations historiques sur les conversations, sur la base de tous les ensembles de données existants, pour obtenir des réponses absolument précises aux questions suivantes, et générez une question appropriée pour chaque ensemble de données en fonction de la description de l'ensemble de données qui peut être liée à la question.
Question : {question} """ sections.append(common_prompt)
# invite relative à l'ensemble des données
data_set = []
for i, collection_name in enumerate(collection_names) :
data_set.append(f"{nom_de_la_collection} : {descriptions_de_la_collection[i]}")
data_set_prompt = f"""Voici toutes les informations relatives à l'ensemble de données. Le format des informations sur les ensembles de données est le suivant : nom de l'ensemble de données : description de l'ensemble de données.
Ensembles de données et descriptions : """ sections.append(data_set_prompt + "\n".join(data_set))
# invite contextuelle
if context :
context_prompt = f"""Ce qui suit est une version condensée de la conversation historique. Ces informations doivent être combinées dans cette analyse pour générer des questions plus proches de la réponse. Vous ne devez pas générer des questions identiques ou similaires pour le même ensemble de données, ni régénérer des questions pour des ensembles de données dont il a été déterminé qu'ils n'étaient pas liés.
Conversation historique : """ sections.append(context_prompt + "\n".join(context))
# invite à la réponse
response_prompt = f"""Sur la base de ce qui précède, vous ne pouvez sélectionner que quelques ensembles de données dans la liste suivante pour générer des questions connexes appropriées pour les ensembles de données sélectionnés afin de résoudre les problèmes susmentionnés. Le format de sortie est json, où la clé est le nom de l'ensemble de données et la valeur est la question générée correspondante.
Ensembles de données : """ sections.append(response_prompt + "\n".join(collection_names))
footer = """Répondre exclusivement dans un format JSON valide correspondant au schéma JSON exact.
Exigences critiques :
- Inclure UN SEUL type d'action
- Ne jamais ajouter de clés non prises en charge
- Exclure tout texte, markdown ou explication non JSON
- Maintenir une syntaxe JSON stricte""" sections.append(footer) return "\n\n".join(sections)
Nous faisons en sorte que le LLM renvoie une sortie structurée sous forme de JSON afin de convertir facilement sa sortie en une décision sur ce qu'il faut faire ensuite.
#### Recherche
Après avoir sélectionné diverses collections de bases de données à l'étape précédente, l'étape de recherche effectue une recherche de similarité avec [Milvus] (https://milvus.io/docs). Comme dans l'article précédent, les données sources ont été spécifiées à l'avance, découpées en morceaux, intégrées et stockées dans la base de données vectorielle. Pour DeepSearcher, les sources de données, locales et en ligne, doivent être spécifiées manuellement. Nous laissons la recherche en ligne pour de futurs travaux.
#### Réflexion
Contrairement à l'article précédent, DeepSearcher illustre une véritable forme de réflexion agentique, en introduisant les résultats précédents en tant que contexte dans une invite qui "réfléchit" à la question de savoir si les questions posées jusqu'à présent et les morceaux extraits pertinents contiennent des lacunes en matière d'information. Cela peut être considéré comme une étape d'analyse.
Voici la méthode de création de l'invite :
``python
def get_reflect_prompt(
question : str,
mini_questions : Liste[str],
mini_chuncks : Liste[str],
) :
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks) :
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
reflect_prompt = f"""Déterminer si des requêtes de recherche supplémentaires sont nécessaires sur la base de la requête originale, des sous-requêtes précédentes et de tous les morceaux de documents récupérés. Si des recherches supplémentaires sont nécessaires, fournir une liste Python de 3 requêtes de recherche au maximum. Si aucune recherche supplémentaire n'est nécessaire, renvoyer une liste vide.
Si la requête initiale consiste à rédiger un rapport et que vous préférez générer d'autres requêtes, renvoyez plutôt une liste vide.
Requête originale : {question}
Sous-requêtes précédentes : {mini_questions}
Morceaux apparentés :
{mini_chunk_str}
"""
footer = """Répondre exclusivement au format List of str valide sans aucun autre texte.""
return reflect_prompt + footer
Une fois de plus, nous faisons en sorte que le LLM renvoie une sortie structurée, cette fois sous forme de données interprétables par Python.
Voici un exemple de nouvelles sous-questions "découvertes" par réflexion après avoir répondu aux sous-questions initiales ci-dessus :
Nouvelles requêtes de recherche pour la prochaine itération : [
"Comment les changements de voix et de l'équipe de production des Simpsons ont-ils influencé l'évolution de la série au fil des saisons ?
"Quel rôle la satire et le commentaire social des Simpson ont-ils joué dans leur adaptation aux problèmes contemporains au fil des décennies ?
Comment Les Simpson a-t-il abordé et intégré les changements dans la consommation des médias, tels que les services de diffusion en continu, dans ses stratégies de distribution et de contenu ?]
Répétition conditionnelle
Contrairement à notre précédent billet, DeepSearcher illustre un flux d'exécution conditionnel. Après avoir réfléchi si les questions et les réponses sont complètes, s'il y a des questions supplémentaires à poser, l'agent répète les étapes ci-dessus. Il est important de noter que le flux d'exécution (une boucle while) est une fonction de la sortie LLM plutôt que d'être codé en dur. Dans ce cas, il n'y a qu'un choix binaire : répéter la recherche ou générer un rapport. Dans les agents plus complexes, il peut y avoir plusieurs choix tels que : suivre un lien hypertexte, récupérer des morceaux, stocker en mémoire, réfléchir, etc. De cette manière, la question continue d'être affinée comme l'agent le souhaite jusqu'à ce qu'il décide de sortir de la boucle et de générer le rapport. Dans notre exemple des Simpsons, DeepSearcher effectue deux tours supplémentaires pour combler les lacunes avec des sous-requêtes supplémentaires.
Synthétiser
Enfin, la question entièrement décomposée et les morceaux récupérés sont synthétisés dans un rapport avec une seule invite. Voici le code permettant de créer l'invite :
``python def get_final_answer_prompt( question : str, mini_questions : Liste[str], mini_chuncks : Liste[str], ) : mini_chunk_str = "" for i, chunk in enumerate(mini_chuncks) : mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n""" summary_prompt = f"""Vous êtes un expert en analyse de contenu de l'IA, doué pour résumer le contenu. Veuillez résumer une réponse ou un rapport spécifique et détaillé basé sur les requêtes précédentes et les morceaux de documents récupérés.
Requête originale : {question}
Sous-requêtes précédentes : {mini_questions}
Morceaux apparentés :
{mini_chunk_str}
"""
return summary_prompt
Cette approche présente l'avantage, par rapport à notre prototype qui analysait chaque question séparément et concaténait simplement les résultats, de produire un rapport dont toutes les sections sont cohérentes entre elles, c'est-à-dire qui ne contient pas d'informations répétées ou contradictoires. Un système plus complexe pourrait combiner des aspects des deux, en utilisant un flux d'exécution conditionnelle pour structurer le rapport, résumer, réécrire, réfléchir et pivoter, et ainsi de suite, ce que nous laissons pour de futurs travaux.
## Résultats
Voici un échantillon du rapport généré par la requête "Comment les Simpsons ont-ils changé au fil du temps ?" avec DeepSeek-R1 qui utilise la page Wikipédia sur les Simpsons comme source :
``txt
Rapport : L'évolution des Simpsons (1989-aujourd'hui)
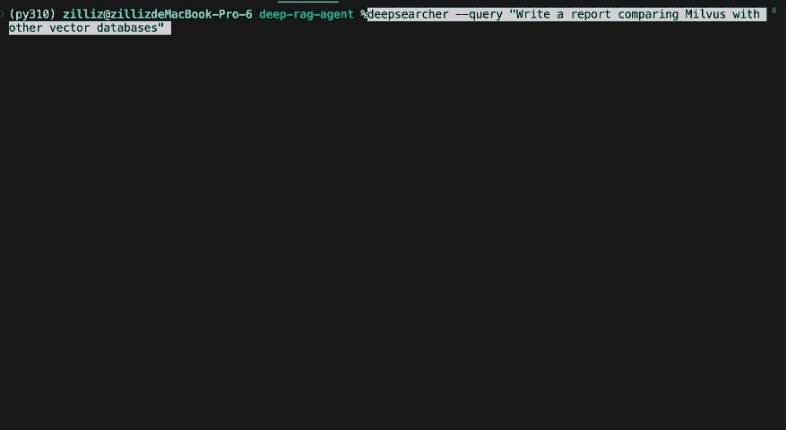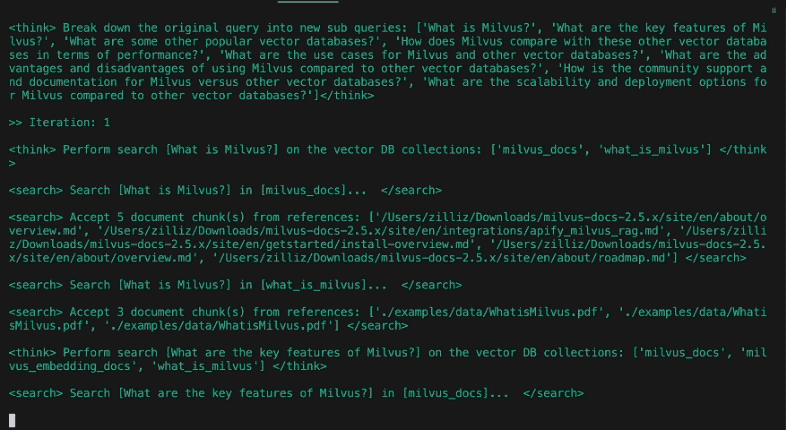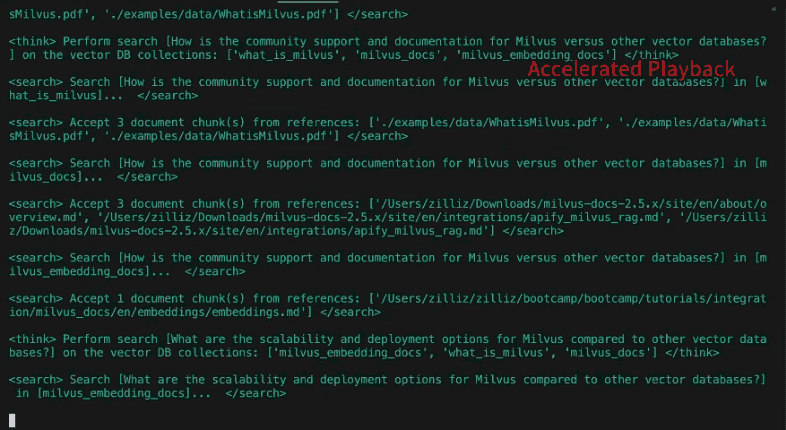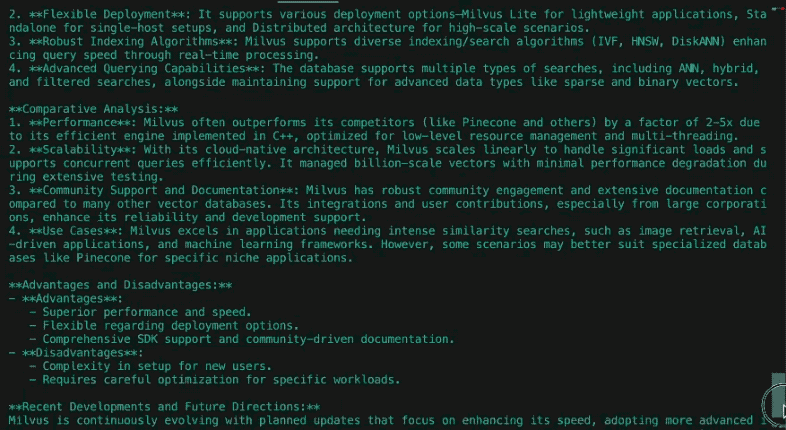
1. Impact culturel et pertinence sociétale
Les Simpson a débuté comme une critique subversive de la vie de la classe moyenne américaine, gagnant en notoriété grâce à sa satire audacieuse dans les années 1990. Phénomène contre-culturel à l'origine, les Simpson ont remis en question les normes en s'attaquant à la religion, à la politique et à la consommation. Au fil du temps, sa domination culturelle s'est affaiblie, car des concurrents comme South Park et Family Guy ont repoussé les limites. Dans les années 2010, la série est passée du statut de précurseur à celui d'institution nostalgique, équilibrant l'attrait de l'héritage avec des tentatives d'aborder des questions modernes telles que le changement climatique et les droits des LGBTQ+, bien qu'avec une résonance sociétale moindre.
...
Conclusion
Les Simpson est passé d'une satire radicale à une institution télévisuelle, naviguant entre les changements technologiques, politiques et les attentes du public. Si son brio de l'âge d'or reste inégalé, sa capacité d'adaptation - par le biais de la diffusion en continu, d'un humour actualisé et d'une portée mondiale - lui permet de conserver sa place de pierre de touche de la culture. La longévité de l'émission reflète à la fois la nostalgie et l'acceptation pragmatique du changement, même si elle est confrontée aux défis de la pertinence dans un paysage médiatique fragmenté.
Vous trouverez [le rapport complet ici] (https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view?usp=sharing), et [un rapport produit par DeepSearcher avec GPT-4o mini] (https://drive.google.com/file/d/1EGd16sJDNFnssk9yTd5o9jzbizrY_NS_/view?usp=sharing) à titre de comparaison.
Discussion
Nous avons présenté DeepSearcher, un agent permettant d'effectuer des recherches et de rédiger des rapports. Notre système est construit sur l'idée de notre article précédent, en ajoutant des fonctionnalités telles que le flux d'exécution conditionnel, le routage des requêtes, et une interface améliorée. Nous sommes passés de l'inférence locale avec un petit modèle de raisonnement quantifié de 4 bits à un service d'inférence en ligne pour le modèle massif DeepSeek-R1, ce qui a permis d'améliorer qualitativement notre rapport de sortie. DeepSearcher fonctionne avec la plupart des services d'inférence comme OpenAI, Gemini, DeepSeek et Grok 3 (bientôt disponible !).
Les modèles de raisonnement, en particulier ceux utilisés dans les agents de recherche, reposent sur l'inférence, et nous avons eu la chance de pouvoir utiliser l'offre la plus rapide de DeepSeek-R1 de SambaNova, qui fonctionne sur leur matériel personnalisé. Pour notre requête de démonstration, nous avons effectué soixante-cinq appels au service d'inférence DeepSeek-R1 de SambaNova, entrant environ 25k tokens, sortant 22k tokens, et coûtant 0,30 $. Nous avons été impressionnés par la vitesse d'inférence étant donné que le modèle contient 671 milliards de paramètres et a une taille de 3/4 de téraoctet. [Pour plus de détails, cliquez ici] (https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency)
Nous continuerons à itérer sur ce travail dans de futurs billets, en examinant d'autres concepts agentiques et l'espace de conception des agents de recherche. Entre-temps, nous invitons tout le monde à essayer DeepSearcher, star us on GitHub, et à nous faire part de vos commentaires !
Ressources
Lecture de fond : "I Built a Deep Research with Open Source-and So Can You !"
Le site web de DeepSeek est disponible sur le site web de DeepSeek, à l'adresse : https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency.
DeepSearcher : Rapport de DeepSeek-R1 sur les Simpsons
DeepSearcher : GPT-4o mini rapport sur Les Simpson

Continuer à lire

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Zilliz Cloud BYOC Upgrades: Bring Enterprise-Grade Security, Networking Isolation, and More
Discover how Zilliz Cloud BYOC brings enterprise-grade security, networking isolation, and infrastructure automation to vector database deployments in AWS