




Appel de fonction avec Ollama, Llama 3.2 et Milvus
Mise à jour le 25 septembre 2024 avec Llama 3.2
L'appel de fonctions avec les LLM revient à donner à votre IA le pouvoir de se connecter au monde. En intégrant votre LLM à des outils externes tels que des fonctions définies par l'utilisateur ou des API, vous pouvez créer des applications qui résolvent des problèmes concrets.
Dans cet article de blog, nous verrons comment intégrer Llama 3.2 avec des outils externes tels que [Milvus] (https://zilliz.com/what-is-milvus) et des API pour créer des applications puissantes et sensibles au contexte.
Introduction à l'appel de fonction
Les LLMs comme GPT-4, Mistral Nemo, et Llama 3.2 peuvent maintenant détecter quand ils ont besoin d'appeler une fonction et ensuite sortir JSON avec les arguments pour appeler cette fonction. Cela rend vos applications d'intelligence artificielle plus polyvalentes et plus puissantes.
L'appel fonctionnel permet aux développeurs de créer :
des solutions basées sur LLM pour l'extraction et le marquage de données (par exemple, l'extraction de noms de personnes à partir d'un article de Wikipédia)
des applications qui peuvent aider à convertir le langage naturel en appels d'API ou en requêtes de base de données valides
des moteurs de recherche de connaissances conversationnels qui interagissent avec une base de connaissances
**Les outils
Ollama** : Apporte la puissance des LLM à votre ordinateur portable, en simplifiant les opérations locales.
Milvus** : Notre base de données vectorielles pour un stockage et une récupération efficaces des données.
Llama 3.2-3B : Version améliorée du modèle 3.1, elle est multilingue et dispose d'une longueur de contexte nettement plus longue (128 Ko), et peut tirer parti de l'utilisation d'outils.
Utiliser Llama 3.2 et Ollama
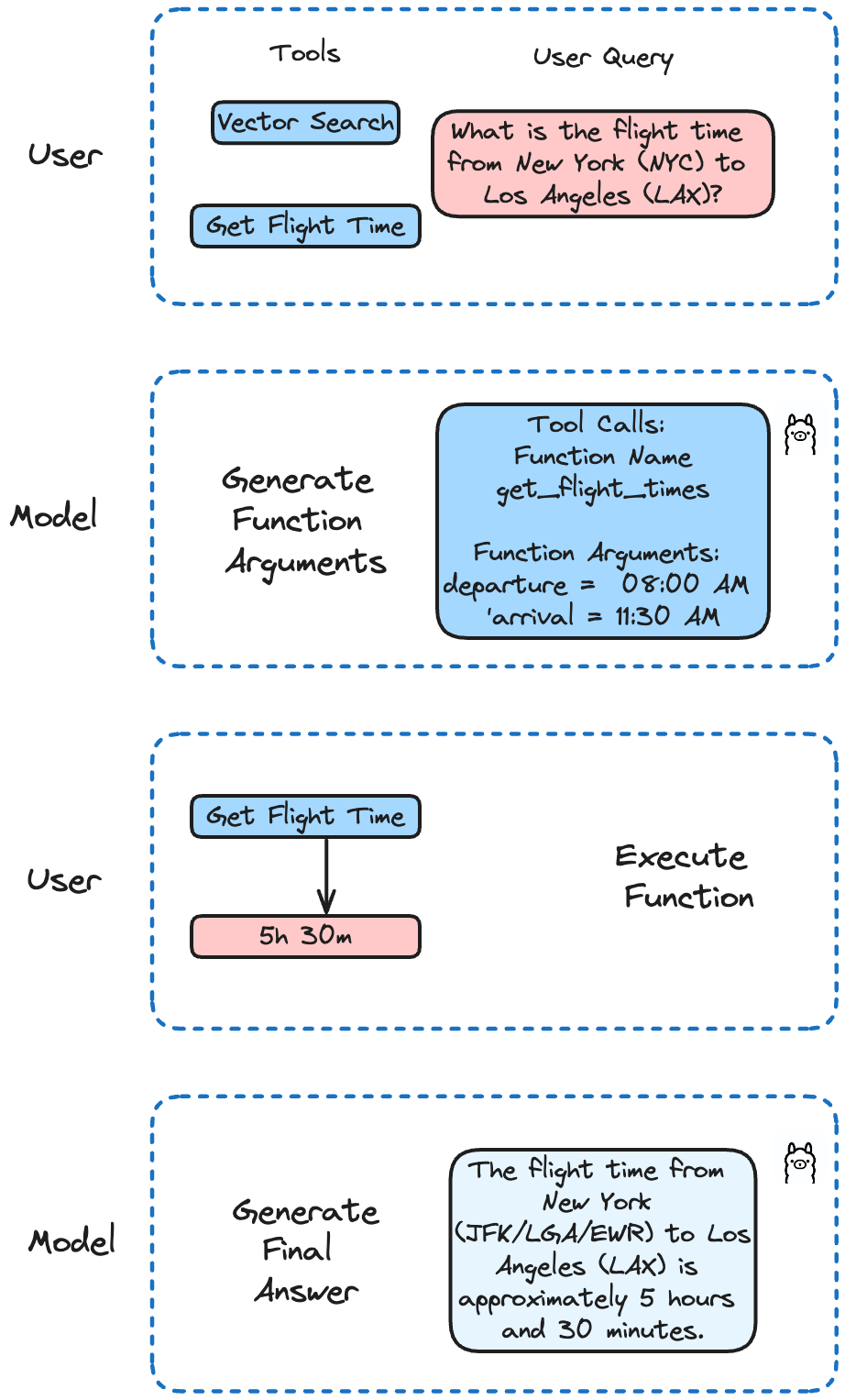
Llama 3.2 a été affiné sur les appels de fonctions. Il supporte les appels de fonctions simples, imbriquées et parallèles, ainsi que les appels de fonctions multi-tours. Cela signifie que votre IA peut gérer des tâches complexes qui impliquent des étapes multiples ou des processus parallèles.
Dans notre exemple, nous mettrons en œuvre différentes fonctions pour simuler un appel à l'API afin d'obtenir les horaires de vol et d'effectuer des recherches dans Milvus. Llama 3.2 décidera de la fonction à appeler en fonction de la requête de l'utilisateur.
Installer les dépendances
Tout d'abord, mettons tout en place. Téléchargez Llama 3.2 en utilisant Ollama :
ollama run llama3.2
Ceci téléchargera le modèle sur votre ordinateur portable, le rendant prêt à être utilisé avec Ollama. Ensuite, installez les dépendances nécessaires :
! pip install ollama openai "pymilvus[model]"
Nous installons Milvus Lite avec l'extension model, qui vous permet d'intégrer des données en utilisant les modèles disponibles dans Milvus.
Insérer des données dans Milvus
Insérons maintenant des données dans Milvus. Ce sont les données que le lama 3.2 décidera de rechercher plus tard s'il pense qu'elles sont pertinentes !
Créer et insérer les données
from pymilvus import MilvusClient, model
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"L'intelligence artificielle a été fondée en tant que discipline universitaire en 1956,
"Alan Turing a été la première personne à mener des recherches substantielles sur l'IA,
"Né à Maida Vale, Londres, Turing a grandi dans le sud de l'Angleterre",
]
vectors = embedding_fn.encode_documents(docs)
# Le vecteur de sortie a 768 dimensions, ce qui correspond à la collection que nous venons de créer.
print("Dim :", embedding_fn.dim, vectors[0].shape) # Dim : 768 (768,)
# Chaque entité possède un identifiant, une représentation vectorielle, un texte brut et une étiquette de sujet.
data = [
{"id" : i, "vector" : vectors[i], "text" : docs[i], "subject" : "histoire"}
for i in range(len(vectors))
]
print("Data has", len(data), "entities, each with fields : ", data[0].keys())
print("Vecteur dim :", len(data[0]["vector"]))
# Créer une collection et insérer les données
client = MilvusClient('./milvus_local.db')
client.create_collection(
collection_name="demo_collection",
dimension=768, # Les vecteurs que nous utiliserons dans cette démo ont 768 dimensions
)
client.insert(nom_de_la_collection="demo_collection", données=data)
Vous devriez alors avoir 3 éléments dans votre nouvelle collection.
Définir les fonctions à utiliser
Dans cet exemple, nous définissons deux fonctions. La première simule un appel API pour obtenir les horaires de vol. La seconde exécute une requête de recherche dans Milvus.
from pymilvus import model
import json
import ollama
embedding_fn = model.DefaultEmbeddingFunction()
# Simule un appel à l'API pour obtenir les temps de vol
# Dans une application réelle, cela permettrait de récupérer les données d'une base de données ou d'une API.
def get_flight_times(departure : str, arrival : str) -> str :
flights = {
NYC-LAX' : {'departure' : '08:00 AM', 'arrival' : '11:30 AM', 'duration' : '5h 30m'},
'LAX-NYC' : {'departure' : '02:00 PM', 'arrival' : '10:30 PM', 'duration' : '5h 30m'},
LHR-JFK' : {'departure' : '10:00 AM', 'arrival' : '01:00 PM', 'duration' : '8h 00m'},
JFK-LHR' : {'départ' : '09:00 PM', 'arrivée' : '09:00 AM', 'durée' : '7h 00m'},
CDG-DXB' : {'départ' : '11:00 AM', 'arrivée' : '08:00 PM', 'durée' : '6h 00m'},
DXB-CDG' : {'departure' : '03:00 AM', 'arrival' : '07:30 AM', 'duration' : '7h 30m'},
}
key = f'{departure}-{arrival}'.upper()
return json.dumps(flights.get(key, {'error' : 'Flight not found'}))
# Recherche de données relatives à l'intelligence artificielle dans une base de données vectorielle
def search_data_in_vector_db(query : str) -> str :
query_vectors = embedding_fn.encode_queries([query])
res = client.search(
nom_de_la_collection="demo_collection",
data=query_vectors,
limit=2,
output_fields=["text", "subject"], # spécifie les champs à renvoyer
)
print(res)
return json.dumps(res)
Donner les instructions au LLM pour qu'il puisse utiliser ces fonctions
Maintenant, donnons les instructions au LLM pour qu'il puisse utiliser les fonctions que nous avons définies.
def run(model : str, question : str) :
client = ollama.Client()
# Initialisation de la conversation avec une requête de l'utilisateur
messages = [{"role" : "user", "content" : question}]
# Premier appel à l'API : Envoi de la requête et de la description de la fonction au modèle
response = client.chat(
model=modèle,
messages=messages,
tools=[
{
"type" : "fonction",
"fonction" : {
"name" : "get_flight_times",
"description" : "Obtenir les temps de vol entre deux villes",
"parameters" : {
"type" : "objet",
"properties" : {
"departure" : {
"type" : "string",
"description" : "La ville de départ (code de l'aéroport)",
},
"arrival" : {
"type" : "string",
"description" : "La ville d'arrivée (code de l'aéroport)",
},
},
"required" : ["départ", "arrivée"],
},
},
},
{
"type" : "fonction",
"fonction" : {
"name" : "search_data_in_vector_db",
"description" : "Recherche de données d'intelligence artificielle dans une base de données vectorielle",
"paramètres" : {
"type" : "objet",
"properties" : {
"query" : {
"type" : "string",
"description" : "La requête de recherche",
},
},
"required" : ["query"],
},
},
},
],
)
# Ajouter la réponse du modèle à l'historique de la conversation
messages.append(response["message"])
# Vérifier si le modèle a décidé d'utiliser la fonction fournie
if not response["message"].get("tool_calls") :
print("Le modèle n'a pas utilisé la fonction, sa réponse était :")
print(response["message"]["content"])
retour
# Traiter les appels de fonction effectués par le modèle
if response["message"].get("tool_calls") :
available_functions = {
"get_flight_times" : get_flight_times,
"search_data_in_vector_db" : search_data_in_vector_db,
}
for tool in response["message"]["tool_calls"] :
function_to_call = available_functions[tool["function"]["name"]]
function_args = tool["fonction"]["arguments"]
function_response = function_to_call(**function_args)
# Ajouter la réponse de la fonction à la conversation
messages.append(
{
"role" : "outil",
"content" : function_response,
}
)
# Deuxième appel à l'API : Obtenir la réponse finale du modèle
final_response = client.chat(model=model, messages=messages)
print(final_response["message"]["content"])
Exemple d'utilisation
Vérifions si nous pouvons obtenir l'heure d'un vol spécifique :
question = "Quelle est la durée du vol entre New York (NYC) et Los Angeles (LAX) ?"
run('llama3.2', question)
Ce qui donne :
Le temps de vol entre New York (JFK/LGA/EWR) et Los Angeles (LAX) est d'environ 5 heures et 30 minutes. Cependant, veuillez noter que cette durée peut varier en fonction de la compagnie aérienne, de l'horaire du vol et des éventuelles escales ou retards. Il est toujours préférable de vérifier auprès de votre compagnie aérienne pour obtenir les informations les plus récentes et les plus précises sur votre vol.
Maintenant, voyons si Llama 3.2 peut effectuer une recherche vectorielle en utilisant Milvus.
question = "Quand l'intelligence artificielle a-t-elle été fondée ?"
run("llama3.2", question)
Ce qui renvoie une recherche Milvus :
données : ["[{'id' : 0, 'distance' : 0.5738513469696045, 'entity' : {'text' : 'L'intelligence artificielle a été fondée en tant que discipline universitaire en 1956', 'subject' : 'history'}}, {'id' : 1, 'distance' : 0.4090226888656616, 'entity' : {'text' : 'Alan Turing a été la première personne à mener des recherches substantielles en intelligence artificielle', 'subject' : 'history'}}]"]
L'intelligence artificielle a été fondée en tant que discipline universitaire en 1956.
Conclusion
L'appel de fonction avec les LLMs ouvre un monde de possibilités. En intégrant Llama 3.2 avec des outils externes tels que Milvus et des API, vous pouvez construire des applications puissantes et contextuelles qui répondent à des cas d'utilisation spécifiques et à des problèmes pratiques.
N'hésitez pas à consulter Milvus, le code sur Github, et à partager vos expériences avec la communauté en rejoignant notre Discord.

Continuer à lire

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.