




Databricks & Spark Connectors
Leverage Databricks' powerful data processing alongside Milvus & Zilliz Cloud's vector index and search with no custom code required
Utilizzate questa integrazione gratuitamente
Combinando le capacità di elaborazione dei dati e di ricerca vettoriale di Milvus & Zilliz Cloud
Databricks è una piattaforma di analisi unificata che semplifica l'elaborazione dei dati e le attività di apprendimento automatico. Si basa su Apache Spark, un sistema di calcolo distribuito open-source. Offre un ambiente collaborativo per ingegneri dei dati, scienziati dei dati e analisti per collaborare a progetti di big data. Databricks elimina le complessità della gestione dei cluster Spark, consentendo agli utenti di concentrarsi sull'analisi dei dati e sulle attività di apprendimento automatico. Offre notebook interattivi, gestione automatizzata dei cluster e supporto integrato per varie fonti di dati e librerie di machine learning. Nel complesso, Databricks migliora l'usabilità e la scalabilità di Spark, rendendo più semplice per le aziende ricavare informazioni da grandi insiemi di dati.
Spark Milvus Connector crea sinergie tra Apache Spark e Milvus, consentendo agli utenti di sfruttare le capacità di elaborazione di Spark insieme alle funzionalità di archiviazione e interrogazione dei dati vettoriali di Milvus. Questa integrazione sblocca una serie di applicazioni preziose, come il trasferimento e l'integrazione dei dati senza soluzione di continuità tra Milvus e diversi sistemi di archiviazione o database, l'elaborazione e l'analisi dei dati semplificate all'interno di Milvus e le operazioni di elaborazione vettoriale efficienti sfruttando Spark MLlib e altre librerie AI.
Questo stesso connettore può essere utilizzato tra Zilliz Cloud e Databricks, semplificando la transizione dei dati dall'elaborazione offline a quella online, importante per la ricerca guidata dall'AI.
I punti chiave dell'integrazione includono:
- Permettere ai lavori Spark che generano vettori di caricare i dati direttamente in Milvus con una semplice chiamata a una funzione di utilità, eliminando la necessità di un codice glue personalizzato o di lavori Spark aggiuntivi.
- L'inserimento diretto dei record di Spark DataFrame in Milvus tramite il connettore Spark-Milvus semplifica l'integrazione, eliminando la necessità di codice per stabilire la connessione e di chiamate API.
Come funziona
Vediamo il processo di trasferimento dei dati da Spark a Milvus. Tradizionalmente, questo compito richiedeva un codice glue complesso per il backend. Tuttavia, con il connettore Spark-Milvus, questo processo è semplificato in una singola chiamata di funzione all'interno dell'applicazione Spark.
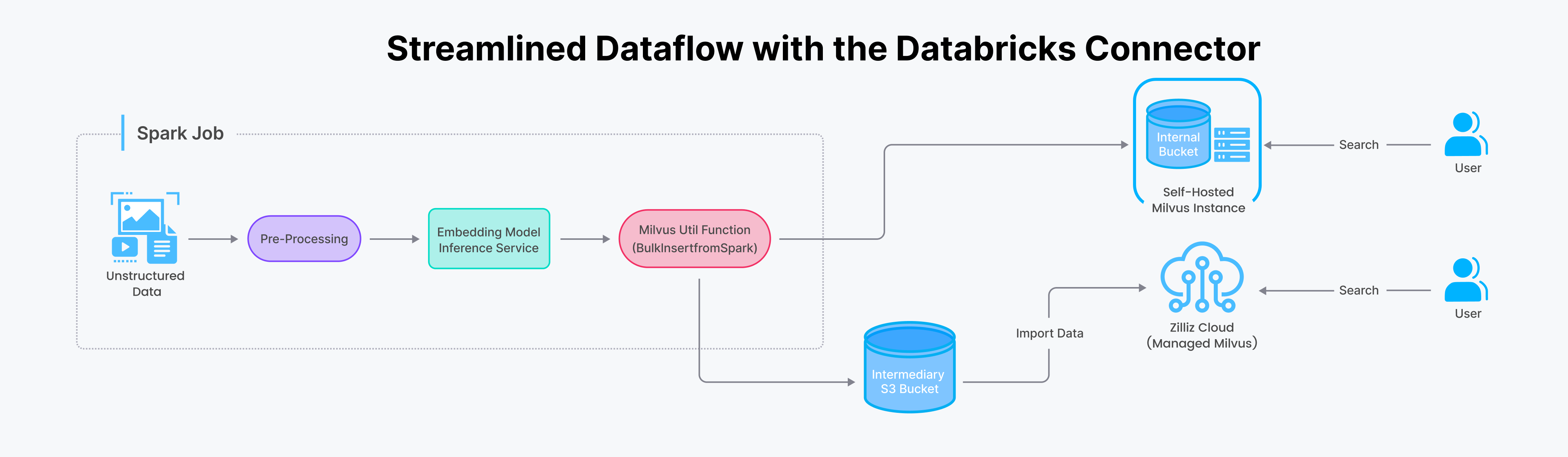 Streamlined Dataflow with the Databricks Connector.png
Streamlined Dataflow with the Databricks Connector.png
Con il connettore Spark/Databricks, è possibile importare dati in Zilliz Cloud (o Milvus) in due modi: in streaming per gli aggiornamenti in tempo reale e in batch per i grandi insiemi di dati. Date un'occhiata ai nostri notebook di esempio per una guida passo-passo su come utilizzarlo efficacemente.
Imparare a utilizzare i connettori Sparks e Databricks
Consultate queste risorse per iniziare a utilizzare Zilliz Cloud e i connettori Spark e Databricks.
Connettore Spark Milvus
Connettore Databricks