Build AI Apps with Retrieval Augmented Generation (RAG)
A comprehensive guide to Retrieval Augmented Generation (RAG), including its definition, workflow, benefits, use cases, and challenges.
Read the entire series
- Build AI Apps with Retrieval Augmented Generation (RAG)
- Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation
- Key NLP technologies in Deep Learning
- How to Evaluate RAG Applications
- Optimizing RAG with Rerankers: The Role and Trade-offs
- Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- How to Enhance the Performance of Your RAG Pipeline
- Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory
- Pandas DataFrame: Chunking and Vectorizing with Milvus
- How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus
- A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG)
- Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)
- Building RAG with Milvus Lite, Llama3, and LlamaIndex
What is Retrieval-Augmented Retrieval (RAG)?
So, what's the deal with Retrieval Augmented Generation, or RAG? First, let's keep in mind what Large Language Models (LLMs) are good at — generating content through natural language processing (NLP). If you ask a Large Language Model to generate a response on data that it has never encountered (maybe something only you know, domain specific information or up to date information that the LLMs haven't been trained on yet), it will not be able to generate an accurate answer because it has no knowledge of this relevant information.
Enter Retrieval Augmented Generation
Retrieval Augmented Generation acts as a framework for the Large Language Model to provide accurate and relevant information when generating the response. To help explain "RAG," let's first look at the "G." The "G" in "RAG" is where the LLM generates text in response to a user query referred to as a prompt. Unfortunately, sometimes, the models will generate a less-than-desirable response.
For example:
Question: What year did the first human land on Mars?
Incorrect Answer (Hallucinated): The first human landed on Mars in 2025.
In this example, the language model has provided a fictional answer since, as of 2024, humans have not landed on Mars! The model may generate responses based on learned patterns from training data. If it encounters a question about an event that hasn't happened, it might still attempt to provide an answer, leading to inaccuracies or hallucinations.
This answer also needs a source listed, or you don't have much confidence in where this answer came from. In addition, more often than not, the answer is out of date. In our case, the LLM hasn't been trained on recent public data, that NASA released about its preparation to get humans to Mars. In any event, it's crucial to be aware of and address such issues when relying on language models for information.
Here are some of the problems that we face with the response generated:
No source listed, so you don’t have much confidence in where this answer came from
Out-of-date information
Answers can be made up based on the data the LLM has been trained on; we refer to this as an AI hallucination
Content is not available on the public internet, where most LLMs get their training data from。
When I look up information on the NASA website about Humans on Mars, I can see much information from NASA on how they prepare humans to explore Mars. Looking further into the NASA site, you can see that a mission started in June 2023 to begin a 378-day Mars surface simulation. Eventually, this mission will end, so the information about humans on Mars will keep changing. With this, I have now grounded my answer with something more believable; I have a source (NASA website)) and I have not hallucinated the answer like the LLM did.
So, what is the point of using an LLM if it will be problematic? This is where the “RA” portion of “RAG” comes in. Retrieval Augmented means that instead of relying on what the LLM has been trained on, we provide the LLM training data with the correct answer with the sources and ask to generate a summary and list the source. This way, we help the LLM from hallucinating the answer.
We do this by putting our content (documents, PDFs, etc) in a structured data to store like a vector database. In this case, we will create a chatbot interface for our users to interface with instead of using the LLM directly. We then create the vector embeddings of our content and store it in the vector database. When the user prompts (asks) our chatbot interface a question, we will instruct the LLM to retrieve the information that is relevant to what the query was. It will convert the question into a vector embedding and do a semantic similarity search using the data stored in the vector database. Once armed with the Retrieval-Augmented answer, our Chatbot app can send this and the sources to the LLM and ask it to generate a summary with the user questions, the data provided, and evidence that it did as instructed.
Hopefully, you can see how RAG can help LLM overcome the above-mentioned challenges. First, with the incorrect data, we provided a data store with correct data from which the application can retrieve the information and send that to the LLM with strict instructions only to use that data and the original question to formulate the response. Second, we can instruct the LLM to pay attention to the data source to provide evidence. We can even take it a step further and require the LLM to respond answer questions with “I don’t know” if the question can’t be reliably answered based on the data stored in the vector db.
How Does RAG Work?
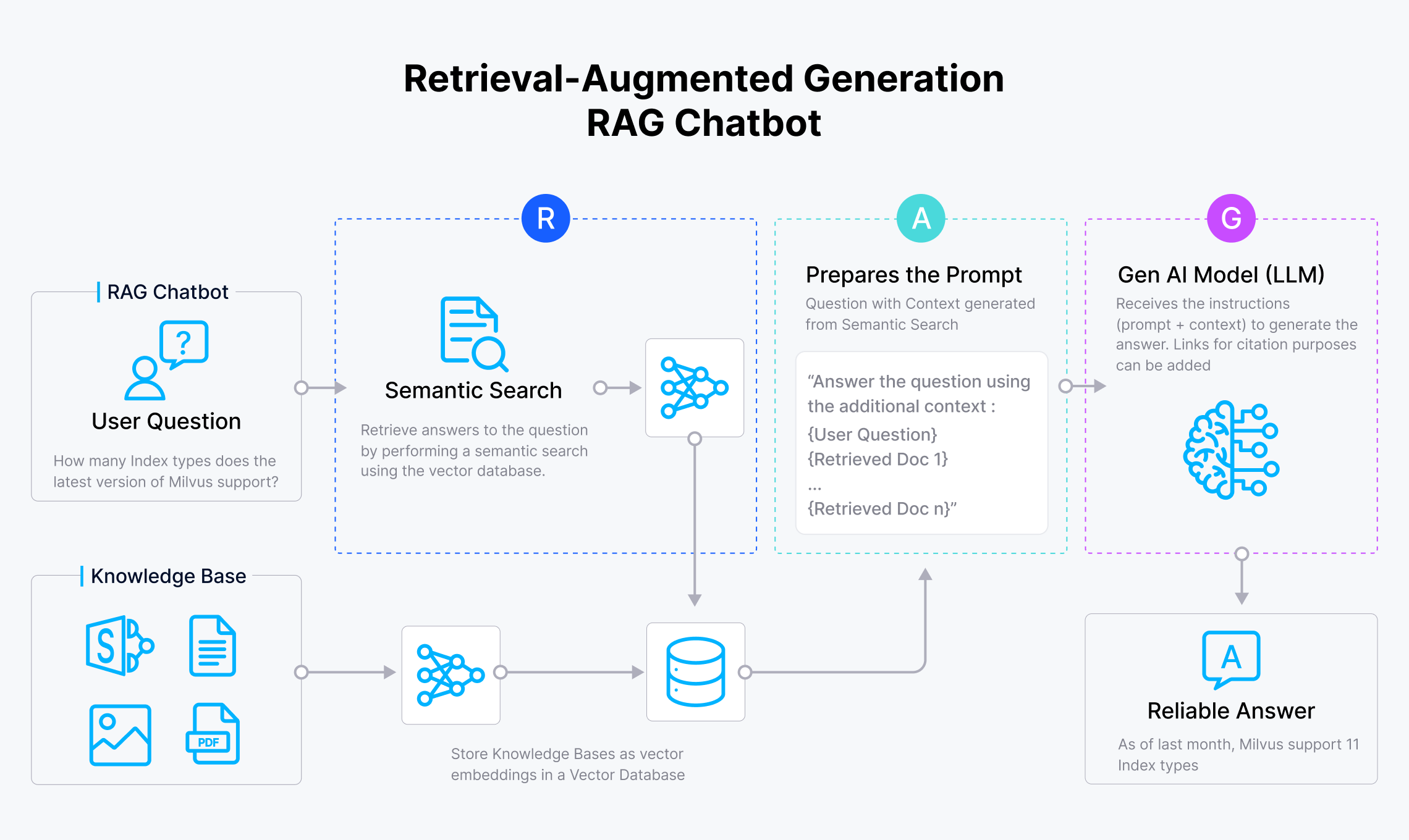 how RAG works
how RAG works
Retrieval-augmented generation (RAG) begins with selecting the data sources that you intend to use for your RAG application to deliver contextually relevant results. These data sources can include anything from text documents and databases to multimedia files, depending on the nature of the information you wish to retrieve. The content from these data sources is then converted into vector embeddings, which are numerical representations of the data. This transformation is achieved using a chosen machine learning model, often a pre-trained model capable of capturing the semantic meaning of the data. Once generated, these vector embeddings are stored in a vector db, a specialized type of database optimized for handling high-dimensional vectors and facilitating efficient similarity searches.
When the application receives a query, such as a question posed to a chatbot, it triggers a semantic search within the vector db. This query is first converted into a vector embedding, similar to the data stored in the database, enabling a comparison based on semantic similarity rather than exact keyword matches. The vector db then conducts a search to identify the most relevant documents or data points based on the proximity of these embeddings in the vector space. The search results, which are contextually relevant documents or data snippets, are combined with the initial query and a prompt, forming a comprehensive input that is sent to the large language model (LLM).
The LLM uses this input to generate a response that is both contextually informed and relevant to the user’s original query. This process not only ensures that the generated information is grounded in reliable data sources but also leverages the power of machine learning to interpret and respond to complex queries with a high degree of accuracy. By integrating a vector database and LLMs, RAG systems can provide more nuanced and precise information retrieval, making them ideal for applications that require sophisticated, context-aware responses.
RAG vs. Fine tuning a Model
Starting with Retrieval-Augmented Generation (RAG) is often an effective entry point, providing a straightforward yet powerful method for many applications. RAG allows you to enhance the performance of large language models (LLMs) by leveraging external data sources, making it an accessible option for developers looking to improve response quality without deep modifications to the underlying model. By incorporating well-designed prompts, you can further refine the responses, ensuring they align more closely with the intended use case.
On the other hand, fine-tuning a model is a more targeted approach that serves specific purposes, particularly when you need to adjust the behavior of the language model itself or adapt it to understand a specialized "language" or domain. Fine-tuning is beneficial when the task requires the model to generate outputs that are highly specific to a particular field, such as legal documents, medical reports, or any other specialized content. By fine-tuning, you can modify the model’s inherent capabilities to better align with the unique requirements of your application.
Rather than viewing RAG and fine-tuning as mutually exclusive, it's often advantageous to see them as complementary strategies. A well-rounded approach could involve fine-tuning the LLM to improve its understanding of domain-specific language, ensuring it produces outputs that meet the particular needs of your application. Simultaneously, using RAG can further boost the quality and relevance of the responses by providing the model with up-to-date, contextually appropriate information drawn from external sources. This combined strategy allows you to capitalize on the strengths of both techniques, resulting in a more robust and effective solution that meets both general and specialized requirements.
Addressing RAG Challenges Head-On
LLMs in the Dark about Your Data
One of the significant limitations of traditional Large Language Models (LLMs) is their reliance on static datasets. These models are trained on vast amounts of data, but their knowledge is inherently limited by the information available up to their training cut-off points. This limitation means that when confronted with queries involving new developments, emerging trends, or domain-specific knowledge that wasn't included in the original training data, LLMs may provide outdated, often inaccurate responses, or even irrelevant responses. The static nature of these models restricts their ability to stay current or adapt dynamically to changes, making them less reliable for applications that demand up-to-date information.
AI Applications Demand Custom Data for Effectiveness
To truly harness the potential of LLMs, especially in specialized fields, organizations must ensure these models can access and understand data specific to their domain. Simply relying on generic, pre-trained models won't suffice for use cases that require precise and contextually accurate answers. For instance, customer support bots need to provide responses tailored to a company’s products, services, and policies. Similarly, internal Q&A bots should be capable of delivering detailed, company-specific information that aligns with current practices and protocols. To achieve this level of specificity, organizations need to integrate their unique datasets with the LLMs, allowing the models to generate responses that are not only relevant but also aligned with the organization's evolving needs. This approach reduces the need for extensive retraining, making it a more efficient solution for keeping AI applications both accurate and effective.
Retrieval Augmentation as an Industry Standard
Retrieval Augmented Generation (RAG) has emerged as a standard practice across various industries, demonstrating its value in overcoming the inherent limitations of traditional Large Language Models (LLMs). Traditional LLMs are powerful, but they are constrained by the static nature of their training data, which doesn't update in real-time and can't incorporate new information post-training. This static nature limits their ability to provide accurate and current responses, particularly in fast-moving industries or scenarios requiring up-to-the-minute data.
RAG addresses this challenge by dynamically connecting LLMs with real-time data retrieval systems. By integrating relevant and up-to-date data directly into the prompts provided to the LLM, RAG effectively bridges the gap between static, knowledge base and real-time information. This process ensures that the responses generated are not only contextually relevant but also current, allowing organizations to leverage AI for tasks that require the most accurate and timely information. As a result, RAG has quickly become a critical tool for industries that rely on AI to enhance their decision-making processes, customer interactions, and overall operational efficiency.
Retrieval Augmented Generation Use Cases
Below are the most popular RAG use cases:
Question and Answer Chatbots: Automated customer support and resolved queries by deriving accurate answers from company documents and knowledge bases.
Search Augmentation: Enhancing search engines with LLM-generated answers to improve informational query responses and facilitate easier information retrieval.
Knowledge Engine for Internal Queries: Enabling employees to ask questions about company data, such as HR or finance policies or compliance documents.
Benefits of RAG
Up-to-date and Accurate Responses: RAG ensures LLM responses are based on current external data sources, mitigating the reliance on static training data.
Reduced Inaccuracies and Hallucinations: By grounding LLM output in relevant external knowledge, RAG minimizes the risk of providing incorrect or fabricated information, offering outputs with verifiable citations.
Domain-Specific, Relevant Responses: Leveraging RAG allows LLMs to provide contextually relevant responses tailored to an organization's proprietary or domain-specific data.
Efficient and Cost-Effective: RAG is simple and cost-effective compared to other customization approaches, enabling organizations to deploy it without extensive model customization.
Reference Architecture for RAG Applications
(also known as LLM RAG Architecture)
Data Preparation of external data
The initial step in building a Retrieval Augmented Generation (RAG) application involves gathering content from your selected data sources. This content must be preprocessed to ensure it is in a usable format for your application. Depending on your chunking strategy, the data is split into appropriate lengths to optimize retrieval and processing efficiency. Following this, the data is converted into vector embeddings using an embedding model aligned with your chosen downstream LLM application. This step lays the groundwork for accurate and efficient data retrieval later in the process.
Index Relevant Information
Once the data has been processed and embedded, the next step is to index this new data, to facilitate quick and relevant searches. Document embeddings are generated, and a Vector Search index is produced using this data. Vector dbs automate the creation of these indexes, offering various data management capabilities that streamline the organization, retrieval, and updating of indexed content.
Context Retrieval (relevant data)
The core functionality of a RAG system is its ability to retrieve data that is most relevant to a user's query. When a user's query is made, the vector db conducts a semantic search to retrieve pertinent data and incorporates it into the prompt used for the LLM's summary and generation process. This ensures that the LLM has access to the most relevant context, enabling it to generate more accurate and contextually appropriate responses.
Build AI Applications
After establishing the retrieval system and query mechanisms, the next step is to integrate these components into a functional AI application. This involves wrapping the prompts, which are now augmented with relevant content, along with the LLM querying components into an endpoint. This endpoint can then be exposed to various applications, such as Q&A chatbots, via a REST API, allowing for seamless interaction between users and the RAG-powered system.
Evaluations
To ensure the ongoing effectiveness and reliability of the RAG system, regular evaluations are essential. This involves assessing the quality of the responses generated by the LLM in response to user queries. Ground truth metrics are used to compare the RAG-generated responses with pre-established correct answers, while metrics like the RAG Triad evaluate the relevance between the user's query, the retrieved context, and the LLM's relevant response. Additionally, specific LLM response metrics, such as friendliness, harmfulness, and conciseness, are used to fine-tune and optimize the system's output. This consistent evaluation process is crucial for maintaining and improving the performance of RAG applications over time.
Key Elements of RAG Architecture
Vector Database
Vector databases play a central role in Retrieval Augmented Generation (RAG) architectures by enabling fast and efficient similarity searches. These vector databases are essential for ensuring that AI applications can access the most relevant data and up-to-date proprietary business data, allowing a keyword search for more accurate and contextually appropriate responses.
Prompt Engineering
This involves creating sophisticated and precise instructions that guide the LLM to generate responses based solely on the content provided. Effective prompt engineering is good for maintaining the relevance and accuracy of the responses, particularly when dealing with complex or domain-specific queries.
ETL Pipeline
An Extract, Transform, Load (ETL) pipeline is needed for handling data ingestion. It manages tasks such as eliminating duplicate data, handling upserts, and performing necessary transformations—like text splitting and metadata extraction—before storing the processed data in the vector db. This step ensures that the data is clean, organized, and ready for efficient retrieval.
LLM
Various LLMs are available, including both open-source and proprietary options. The choice of LLM depends on the specific requirements of the application, such as computational and financial costs such as the need for domain-specific knowledge, language support, and response accuracy.
Semantic Cache
A semantic cache, such as GPT Cache, stores the responses generated by the LLM. This caching mechanism is beneficial for reducing operational costs and improving performance by reusing previously generated responses for similar queries, thereby minimizing the need for redundant computations.
RAG Tools
Third-party tools like LangChain, LLamaIndex, and Semantic Kernel are invaluable in building Retrieval Augmented Generation systems. These tools are often LLM-agnostic, providing flexibility in integrating different LLMs and enabling developers to construct robust and adaptable RAG systems.
Evaluation Tools & Metrics
To ensure the quality and effectiveness of Retrieval Augmented Generation applications, it's important to employ evaluation tools and metrics. Tools like TruLens, DeepEval, LangSmith, and Phoenix help assess the performance of LLMs and RAG systems, offering insights into areas for improvement and ensuring that the generated outputs meet the desired standards.
Governance and Security
Implementing strong governance and security measures is critical for maintaining the integrity of Retrieval Augmented Generation systems. This includes protecting sensitive data, ensuring compliance with regulatory requirements, and establishing protocols to manage and monitor access to the RAG infrastructure.
Navigating the RAG Architectural Landscape
In AI, companies see that Retrieval Augmented Generation is a game-changer, not just a tool. It seamlessly blends LLMs with a vector db to retrieve up to date information, delivering responses that are accurate and current and industry-specific. Retrieval Augmented Generation leads AI towards a future where accuracy meets flexibility, and today's language models become tomorrow's smart conversationalists. There is a lot to learn about how retrieval augmented generation works, especially as we work towards putting out Generative AI applications into production.
The journey has just begun, and with RAG at the helm, the possibilities are boundless for modern information retrieval systems.
Resources for Building RAG Applications
 Chris Churilo
Chris ChuriloChris Churilo is the VP of Marketing (or ALT) at Zilliz where she leads all community, developer relations, and marketing efforts. Prior to Zilliz, Chris was a founding member of the InfluxData’s go to market efforts and helped propel the time series database platform to dominance in the market. In earlier roles she defined and designed a SaaS monitoring solution at Centroid, and prior to that she was the VP of product management at iPass and was the LOB for several cloud services that required her to track the business and operational metrics and analytics to help identify and resolve issues.
- What is Retrieval-Augmented Retrieval (RAG)?
- Enter Retrieval Augmented Generation
- How Does RAG Work?
- RAG vs. Fine tuning a Model
- Addressing RAG Challenges Head-On
- Retrieval Augmentation as an Industry Standard
- Retrieval Augmented Generation Use Cases
- **Benefits of RAG**
- Reference Architecture for RAG Applications
- Key Elements of RAG Architecture
- Navigating the RAG Architectural Landscape
- Resources for Building RAG Applications
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free